





1. Introduction
The TOnes and Break Indices (ToBI) convention serves as an annotation system designed for labeling prosody at the phonology level (Jun, 2022). Initially developed between 1991 and 1994 for annotating databases of spoken Mainstream American English (Silverman et al., 1992), it has since been adapted for various languages, including Seoul Korean (Jun, 2000). Grounded in the Auto-segmental Metrical (AM) Theory (e.g. Beckman & Pierrehumbert, 1986), ToBI conventions utilize binary level tones, High (H) and Low (L), to annotate pitch accents and edge tones (Beckman et al., 2005). With the aim of comprehending the phonological properties of intonation, ToBI tone labels are devised to represent underlying tonal targets that are systematically meaningful across native speakers of the language variety (Jun, 2022).
K-ToBI (Beckman & Jun, 1996; Jun, 2000),1 the ToBI convention tailored for Seoul Korean, stands out due to its inclusion of the phonetic tone tier in its third version (Jun, 2000). The tier delineates “non-distinctive yet categorical tonal targets” (Jun, 2022:159), interpreted as ‘not yet’ distinctive based on current knowledge. The inclusion of the phonetic tone tier stemmed from the aspiration of the developer “to determine what factors and conditions trigger such variation, and thus improve the current model of Korean intonational phonology” (Jun, 2022:159-160). It signifies an open invitation for future research to refine our understanding of Korean intonation by building upon the existing K-ToBI framework.
However, it is notable that certain studies may excessively confine their analyses within the bounds of the K-ToBI convention. Previous research sometimes assumed utterances unequivocally belong to the same intonational category without further investigation solely based on identical Intonation Phrase (IP)-final tones in K-ToBI. This simplistic perspective results in an excess of many-to-many relationships between intonation and (para)linguistic factors (e.g. Park, 2012). Furthermore, the guidelines for labeling IP-final tones in Jun (2000) are occasionally perceived as definitive (e.g. Jeong, 2002; Kim et al., 2008), whereas they should be regarded as a framework for further exploration of Korean intonation.
This study aims to build upon the foundation laid by K-ToBI to refine our understanding of Korean intonation utilizing Korean Intonation Corpus (KICo), a large speech corpus comprising 240 hours of recordings from forty native Seoul Korean speakers and forty L2 learners of Korean. Given that the labeling process is ongoing, we extracted data pertaining to the interjection ani from KICo for analysis in this study. In addition to labeling our database according to the K-ToBI convention, we conducted acoustic analyses on the final syllable aligned with the IP-final tone.2 Specifically, we scrutinized the F0 characteristics to determine whether there are any meaningful acoustic cues not readily discernible through the binary tones alone.
We selected the interjection ani for three reasons. First, it is a basic word with high frequency in spoken Korean, rendering our findings pertinent for practical applications such as speech synthesis, speech recognition, and Korean language education. Second, it serves dual pragmatic purposes - as both a negation and a turn-initial marker - without undergoing any segmental alternations (Kim, 2016; Yang, 2002). This emphasizes the weight of its prosody in effectively conveying meanings, which could potentially lead to clear and informative outcomes. Third, its usage across different speech levels enables us to explore the impact of politeness on Korean intonation, aligning with studies on the global acoustic profile of Korean polite speech (Grawunder & Winter, 2010; Winter & Grawunder, 2012). Consequently, our main research questions regarding ani in Seoul Korean are twofold:
2. Data and Method
In Korean, the interjection ani is predominantly recognized as a negative response to Yes/No interrogatives. For instance, it is commonly used to indicate “No” to questions like “Are you sleeping?” or “Is there any problem?.” Beyond its primary role, ani can also function as a discourse marker, often as a turn-initial particle in ani-prefaced sentences (Kim, 2016; Yang, 2002), similar to ‘wait’ in phrases like “Wait, really?” and “Wait, how can that be?,” providing a moment of pause or interjection.
Given that the Korean Standard Language Dictionary (KSLD) serves as the primary reference of KICo3 and includes two pragmatic meanings of ani, both are incorporated into KICo. The definition of ani in the KSLD are as follows, translated into English by the first author:
-
Meaning 1: A word used to negatively answer a question posed by a junior or an equal.
-
Meaning 2: A word used to express surprise, awe, or puzzlement.
Meaning 1 aligns with the primary function of ani as a negation, while Meaning 2 also reflects the secondary function as a discourse marker to initiate conversational turns. This is exemplified in the KSLD, where ani is used to initiate a dialogue or turn:
-
ani, geureol suga inni? (Wait, can that really be?)
-
ani, beolsseo dochakhaenni? (Wait, have you arrived already?)
-
ani, ige eotteoke doen irinya. (Wait, what in the world happened here?)
Meanwhile, the description “asked by a junior or an equal” in Meaning 1 relates to the speech level of ani, which is categorized as Intimate. The speech levels in Korean were traditionally divided into six levels based on politeness: Deferential (-(su)pnita), Polite ((-a/e)yo), Blunt (-(s)o), Familiar (-ney), Intimate (-a/e), and Plain ((-[nu]n)ta), ranging from the most polite to the least (Sohn, 2001). While the speech level of ani is Intimate, suitable for addressing juniors or equals, it can be flexibly inflected to various speech levels. Notably, when ani is used as a discourse marker, it is not exclusively employed in its Intimate form and is not utilized in other speech levels, even when followed by a Polite sentence (Yang, 2002:114)4. Accordingly, this study analyzed only the Intimate level for Meaning 2, while analyzing both Intimate and Polite levels for Meaning 1.
KICo is a speech corpus specifically designed to study the intonation of Korean, responding to the need for guidelines to teach intonation to L2 learners (Kim, 2023). KICo comprises two main sections: KICo-N (natives) and KICo-L (learners). KICo-N contains recordings from native Seoul Korean speakers, while KICo-L includes recordings from Mongolian and Vietnamese learners of Korean.
The ani and aniyo data analyzed in this study were sourced from KICo-N. The participants were native Seoul Korean speakers, all born and raised in either Seoul or Gyeonggi Province (the suburban area surrounding Seoul), and without any speaking or hearing impairments. The speech data were collected using the online experimental platform Finding Five (FindingFive Team, 2023). All recordings were supervised by a research assistant in a soundproof booth to ensure quality and consistency. The setup included an audio interface (AG03, Yamaha) connected to a laptop and a head-mounted microphone (SM10A, Shure), with a sampling rate of 48k samples per second.
The scripts used to elicit ani speech included three variations: Intimate ani with Meaning 1 (henceforth, ‘Ani_1’), Intimate ani with Meaning 2 (henceforth, ‘Ani_2’), and Polite ani with Meaning 1 (henceforth, ‘Aniyo_1’ or ‘Aniyo’). Polite ani with Meaning 2 was excluded, as ani with Meaning 2 is primarily used in its Intimate form. Each item was represented by eleven short scripts, resulting in a total of thirty-three scripts for each speaker (N=1,320=33 scripts×40 speakers). The sample Romanized scripts for ani, along with their English translations are provided as follows:5
Our speech data were annotated using Praat (Boersma & Weenink, 2024), with TextGrid tiers added for organization. Each TextGrid file comprises four tiers: three interval tiers and a point tier. Figure 1 presents a screenshot of a fully annotated TextGrid file:
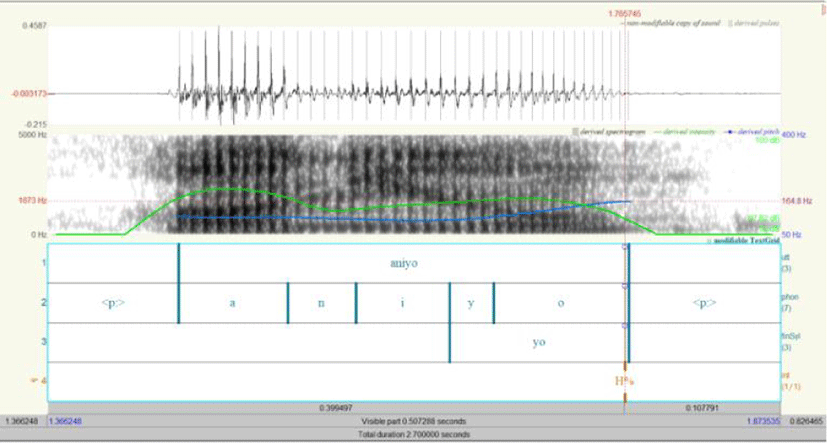
As depicted in Figure 1, the interval tiers were designated for marking the entire utterance duration (‘utt’), phoneme intervals (‘phon’), and the final syllable interval (‘finSyl’). The point tier was assigned for transcribing the IP-final tones based on the K-ToBI convention (Jun, 2000) (‘int’). The first and second tiers were attributed semi-automatically through WebMAUS (Kisler et al., 2017; Schiel, 1999), as the Korean Phonetic Aligner (Yoon, 2021; Yoon & Kang, 2013), the sole forced alignment tool for Korean, was not operational due to technical issues6. Since WebMAUS lacks a specific Korean option, alignment adjustments were performed manually by research assistants and further refined by the first author.
Five F0 parameters were selected to examine the acoustic variability of the final syllable, aiming to discern if IP-final tones, despite appearing identical, exhibit distinct acoustic realizations. These parameters include the valley, peak, range, and slope of F0. We focused on F0 characteristics because F0 curves form the fundamental basis for transcribing IP-final tones. Figure 2 shows the F0 curves of an Ani_1 with H% and an Aniyo_1 with LH%:
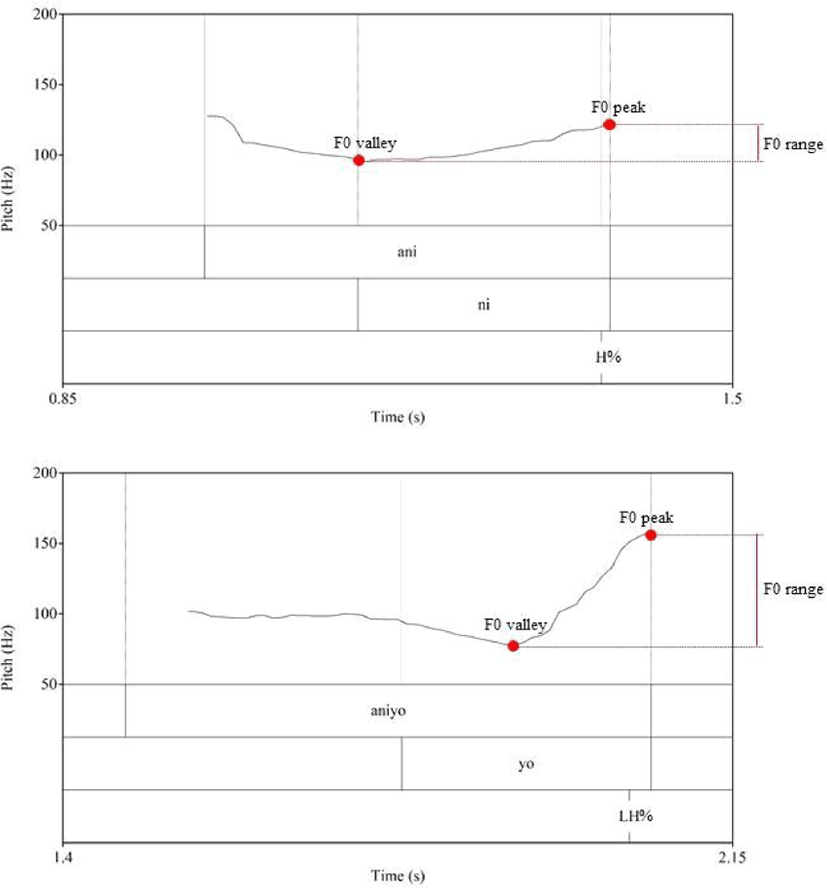
All measurements were conducted in Praat by extracting an F0 contour (Pitch object) using Praat’s “To Pitch…” function. The measurements primarily relied on temporal segmental information of the IP-final syllable, as depicted in Figure 2. Additionally, contour tones were further subdivided to measure local changes. For instance, LH% was divided into L and H to analyze each component separately. Figure 3 illustrates the measurements of the tone segments (L and H in this case) for Aniyo_1 with LH%:
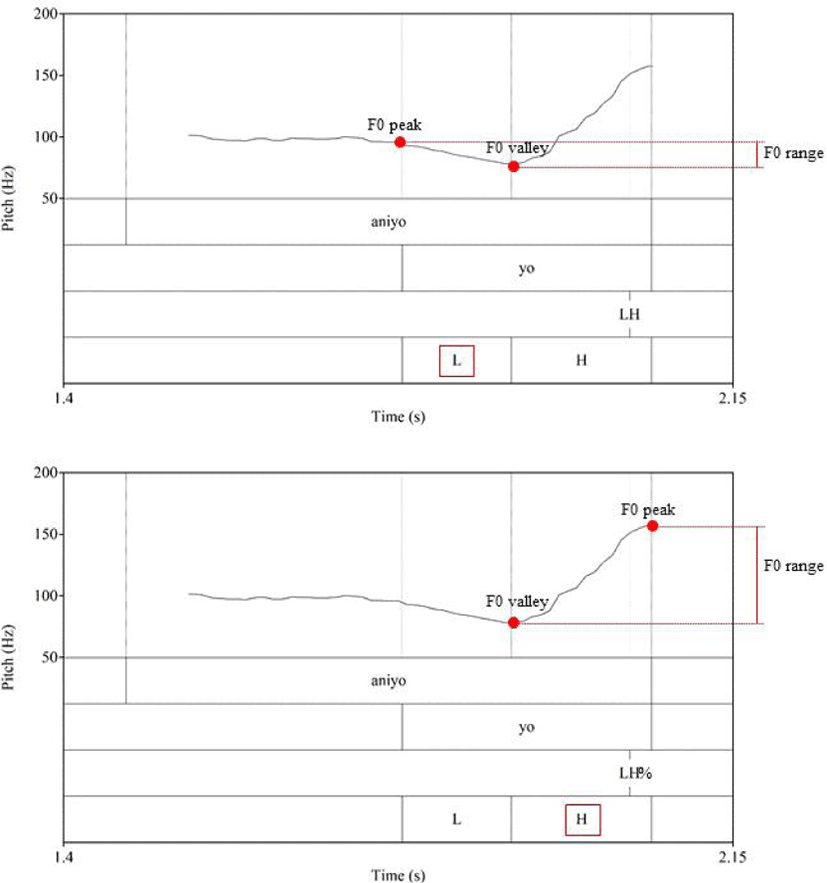
The values of F0 valley and peak were obtained using functions in Praat: ‘Get minimum…’ for the valley, and ‘Get maximum…’ for the peak. The F0 range was calculated by subtracting F0 valley from F0 peak (i.e., F0 range=F0 peak–F0 valley). The F0 slope was calculated by dividing F0 range by the duration of the segment (i.e., F0 slope=F0 range/duration). The duration itself was obtained by subtracting the start point from the end point of the segment (i.e., duration=end point–start point).
Chi-square tests of independence were performed at a significance level of 95% using R (R Core Team, 2020). To address the issue of sparse data in contingency tables, cells with fewer than five cases were aggregated under ‘Others’ by using the pooling method (Bresnahan & Shapiro, 1966).
The analyses were performed to evaluate whether the changes in the IP-final tone, as transcribed according to the K-ToBI convention, were independent of the meaning (Ani_1 vs. Ani_2) or the speech level (Ani_1 vs. Aniyo_1). More specifically, we tested two hypotheses below:
Welch’s t-tests, which assume unequal variances between two samples, were conducted at a significance level of 95% using R (R Core Team, 2020). These tests were applied to determine if the F0 characteristics of the final syllable change significantly between (1) Ani_1 and Ani_2, and (2) Ani_1 and Aniyo_1, despite having the same IP-final tone.
Considering only IP-final tones that accounted for more than 5% of each group, the comparison was narrowed down to Ani_1 H% vs. Ani_2 H%, Ani_1 H% vs. Aniyo_1 H%, and Ani_1 LH% vs. Aniyo_1 LH%. More specifically, we tested the following three hypotheses:
3. Results
Chi-square tests of independence were performed to examine the relationship between IP-final tones, transcribed by the K-ToBI convention, and two variables: the meaning of ani (Ani_1 vs. Ani_2) and the speech level of ani (Ani_1 vs. Aniyo_1). The results are summarized in Table 1:7
| Meaning (Ani_1 vs. Ani_2) |
Speech level (Ani_1 vs. Aniyo_1) |
|
|---|---|---|
| DoF | 4 | 2 |
| p-value | <0.001*** | 0.499 |
| χ2-value | 543.09 | 1.391 |
First, concerning the relationship between IP-final tones and the meaning of ani, the test revealed a significant association (χ2(4)=543.09, p<0.001). This indicates that speakers significantly alter the IP-final tones based on the meaning of ani. This finding is consistent with the visual distribution of IP-final tones illustrated in Figure 4:
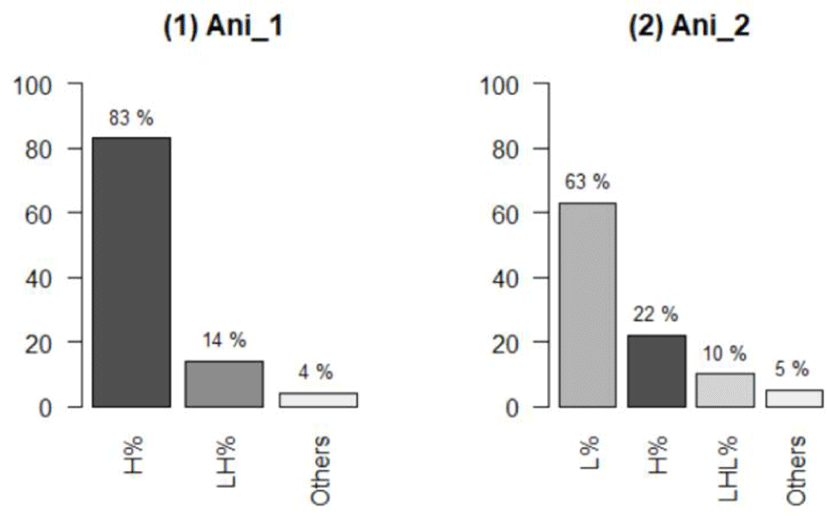
As shown in (1) of Figure 4, the dominant IP-final tone for Ani_1 is H% (82.46%), followed by LH% (14.5%). The ‘Others’ category for Ani_1 includes L% (2.90%) and HLH% (0.14%)8. Conversely, as described in (2), the dominant IP-final tone of Ani_2 is L% (63.41%), with H% (21.59%) and LHL% (10.45%) following. In this case, ‘Others’ includes LH% (2.27%), HL% (1.82%), HLH% (0.23%) and HLHL% (0.23%).
In contrast, the association between IP-final tones and the speech level of ani (Ani_1 vs. Aniyo_1) is not significant (χ2(2)=1.391, p=0.499). This suggests that the speech level does not significantly influence the variation in IP-final tones for ani. This finding is also in line with Figure 5:
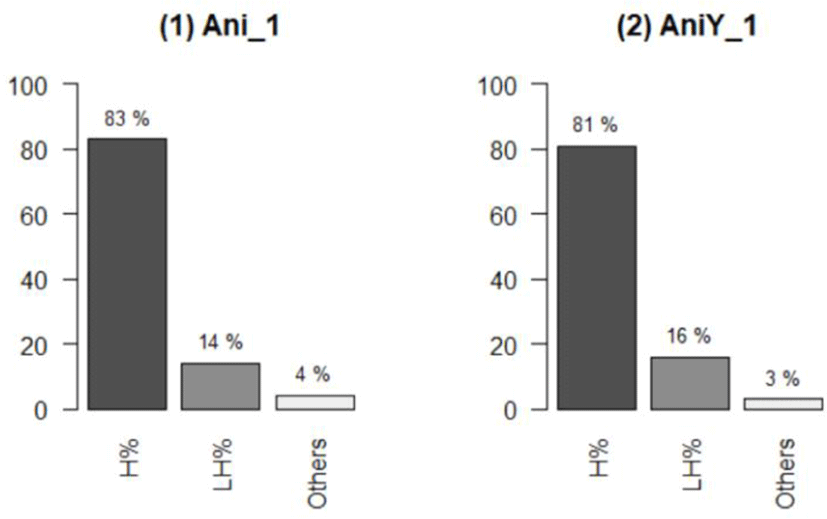
As shown in (2) of Figure 5, the most frequent IP-final tone for Aniyo_1 in our data is H% (81.36%), followed by LH% (15.91%). The ‘Others’ category includes L% (2.5%) and HL% (0.23%). Notably, the distribution pattern of Aniyo_1 closely mirrors that of Ani_1 shown in (1), with H% being the most common IP-final tone and LH% the second most common.
A series of Welch’s t-tests were performed to explore any significant differences in F0 characteristics of the final syllable when Ani_1 and Ani_2, as well as Ani_1 and Aniyo_1, shared the same IP-final tone. Focusing on the IP-final tones that accounted for more than 5% of occurrences in each group, three comparisons were analyzed: Ani_1 H% vs. Ani_2 H%, Ani_1 H% vs. Aniyo_1 H%, and Ani_1 LH% vs. Aniyo_1 LH%. Our acoustic analyses suggest that both the meaning and speech level of ani significantly influence the F0 characteristics of the IP-final syllable.
First, Table 2 presents the results of acoustic analyses on Ani_1 with H% vs. Ani_2 with H%:9
The results reveal significant variation in the production of H% tones in ani according to their meaning. Notably, Ani_1 exhibits the most pronounced effect size among all other F0 measures, displaying a significantly sharper F0 slope compared to Ani_2 [t(110.32)=–3.646, p<0.001, Cohen’s d=0.497]. This indicates a steeper rise in the F0 curve at the final syllable with an H% tone in Ani_2. Also, Ani_1 demonstrates a wider F0 range than Ani_2, though with a smaller effect size [t(104.96)=–5.474, p<0.001, Cohen’s d=0.226], suggesting greater F0 variability in the H% of Ani_2. This difference in the F0 range primarily stems from Ani_1 having a significantly lower F0 valley than Ani_2, while the F0 peak doesn’t show any significant variation between the two.
Second, Table 3 displays the results of the acoustic analyses on Ani_1 and Aniyo_1, both realized with the H% tones:
The findings indicate that H% tones in ani also exhibit variation by speech level, albeit significant differences are limited. Notably, the F0 valley was the sole variable to significantly differ across speech levels, demonstrating a small effect size [t(718.5)=–2.555, p=0.011, Cohen’s d=0.19], with Ani_1 (M=154.01, SD=47.21) exhibiting a lower valley than Aniyo_1 (M=168.81, SD=56.21). Although not statistically significant, there was a noticeable trend in the F0 range, where Ani_1 H% exhibited a marginally wider range (M=70.04, SD=36.10) compared to Aniyo_1 H% (M=52.96, SD=29.96).
Third, Table 4 shows the results of the acoustic analyses on the final syllable of Ani_1 and Aniyo_1, both realized with the LH% tones:
Table 4 reveals that LH% tones in Ani_1 exhibit variation by speech level, particularly notable in the F0 slope with a large effect size [t(121.12)=–2.901, p=0.004, Cohen’s d=0.514]. This suggests a steeper slope for Aniyo_1 LH% (M=360.22, SD=180.86) compared to Ani_1 LH% (M=279.56, SD=192.54). However, Table 4 does not specify whether the difference is driven by the L component or the H component of the contour tone. Thus, additional acoustic analyses were conducted on the individual tone components (L, H) of the LH% tones in Ani_1 and Aniyo_1, with the results summarized in Tables 5 and 6:
Tables 5 and 6 indicate that the L component significantly influences the F0 slope in LH% tones for Ani_1 and Aniyo_1. Specifically, the F0 slope of the L component in Aniyo_1 is notably steeper than in Ani_1, with a large effect size [t(114.19)=–3.617, p<0.001, Cohen’s d=0.613]. Additionally, a trend was observed in the F0 range of the L component, with Ani_1 displaying a marginally wider range (M=6.98, SD=4.46) than Aniyo_1 H% (M=5.61, SD=3.757), although this did not reach the significance threshold [t(115.92)=1.884, p=0.062]. Conversely, the F0 characteristics of the H component did not differ significantly between Ani_1 and Aniyo_1.
4. Discussion
In this section, we discuss the implications of our results to answer the two central research questions posed in the introduction section: Do the IP-final tones of ani differ by meaning? Do the IP-final tones of ani differ by speech level? By examining these questions, we advocate for a deeper analysis of the F0 curve, extending beyond the categorical labels assigned by the ToBI conventions, to enrich our understanding of intonation.
In this study, we investigated whether the intonation of ani differs depending on its meaning. We hypothesized that ani utilizes prosodic variation to convey its two distinct meanings: as a negation (Ani_1) and as a discourse marker (Ani_2). While previous research by Yang (2002) and Kim (2016) explored the extended functions of ani, they did not closely examine the prosodic distinctions between these two meanings.
Based on Chi-square tests of independence, our ToBI-based analyses uncovered a significant relationship between the meaning of ani and its IP-final tones. Specifically, we found that H% was more prevalent in Ani_1, while L% was more common in Ani_2. However, relying solely on a categorical analysis according to K-ToBI (Jun, 2000) might have led us to underestimating the distinctiveness of intonation in Ani_2, where H% accounted for 22% of the data. This could create the impression of substantial overlap in the usage of H% between Ani_1 and Ani_2.
However, our acoustic analyses painted a different picture. They revealed that, despite sharing the label of H%, the tones in Ani_1 and Ani_2 are phonetically distinct. Specifically, Ani_1 exhibited a significantly steeper F0 slope, a wider F0 range, and a lower F0 valley compared to Ani_2, though the F0 peak did not significantly vary by meaning.
These findings clarify that the subtle yet significant differences in intonation, which might be overlooked in a purely categorical approach, become evident when analyzing the actual phonetic details. Thus, while ToBI serves as a valuable scaffold for intonation studies, further investigation into acoustic properties may be necessary for a comprehensive understanding of Korean intonation.
In this study, we hypothesized whether the intonation of ani differs based on the speech level, specifically between Intimate and Polite forms. Previous research has suggested that Korean speakers adjust their overall F0 characteristics, such as average, range, and standard deviations, according to the politeness or formality level of speech (Grawunder & Winter, 2010; Winter & Grawunder, 2012)10. Still, these studies did not directly investigate the relationship between intonation and politeness.
Our results indicate that, according to the categorization by K-ToBI, the IP-final tones of ani do not significantly vary based on the speech level. This observation is primarily due to a substantial overlap in IP-final tones: H% tones constitute over 80% of both Ani_1 and Aniyo_1 data, while LH% tones are also present in 14% of Ani_1 and 16% of Aniyo_1 data11.
However, our acoustic analyses show notable variations in the F0 characteristics, even within categorically identical IP-final tones. Although both Ani_1 and Ani_2 include the H% tone, as well as the LH% tone, they exhibit distinct F0 characteristics at the IP-final syllable. Specifically, Ani_1 demonstrated a significantly lower F0 valley compared to Aniyo_1 for the H% tone, albeit with a small effect size. Regarding the LH% tone, Aniyo_1 exhibited a significantly steeper F0 slope than Ani_1, with this difference significantly influenced by the F0 slope of the L component.
These findings suggest that significant intonational differences between speech levels may exist, which might not have been evident in a categorical analysis but become apparent through further phonetic analyses. Therefore, while ToBI provides a useful framework, additional analyses on the phonetic realization of tones may contribute to a more complete understanding of Korean intonation.
5. General Discussion and Conclusion
This study investigated the variation in the intonation of Seoul Korean ani across different meanings and speech levels using data from KICo, employing two main approaches:
-
First, we categorically labeled the IP-final tones in the dataset following the K-ToBI convention (Jun, 2000). Chi-square tests of independence were then used to explore whether these tones were significantly associated with either meaning (Ani_1 vs. Ani_2) or speech level (Ani_1 vs. Aniyo_1). While we observed considerable overlap between groups, significant relationships emerged between the meaning of ani and its IP-final tones.
-
Second, we scrutinized the F0 characteristics of the final syllable of ani to determine if the observed many-to-many relationships between intonation and meaning/speech level could be clarified. The results of Welch’s t-tests indicated that these apparent overlaps could indeed be significantly distinguished.
In summary, our study highlights the necessity of further analysis on phonetic intonation beyond ToBI-based categorical labels. By examining the F0 characteristics of the IP-final syllable, we gained a clearer understanding of the previously ambiguous connections between meaning/speech level and intonation. ToBI serves as a valuable tool and framework for studying intonation, as it facilitates segmentation, which is not only practical but necessary for analyzing intonation from a linguistic perspective (Bolinger, 1949). However, it’s essential to explore beyond these categorical labels to gain a deeper understanding of the “distinctiveness” of intonation, thus enhancing our understanding of prosody.