





1. Introduction
The Korean language does not have the phonemic contrast between /r/ and /l/ whereas English does. Due to a lack of the phonemic contrast, Korean learners of English have difficulties in distinguishing English /r/ and /l/ sounds in perception and production (Borden et al., 1983; Jang, 2005; Kim & Rhee, 2019). When the two sounds are hard to distinguish from each other, the production of the sequence of the two, /rl/, becomes even harder. In addition, Korean phonology does not allow coda clusters to surface [*Complex Coda>>Max(C)] unlike English. Due to the difficulties in production, perception, and phonological constraints, the English word-final /rl/ cluster is often simplified as one liquid sound by Korean learners of English. As a result, the English words world [wɜ:ɹld] and word [wɜ:ɹd] are hard for Korean speakers to differentiate in their perception and production. Against this backdrop, the present study examines the production of the word-final /rl/ clusters by English and Korean speakers with a novel approach, the dynamic time warping (DTW) algorithm (Giorgino, 2009).
Previous research has focused more on Korean speakers' production of English /r/ and /l/ separately, instead of the cluster of the two (Ingram & Park, 1998; Kang, 1999; Kim & Rhee, 2019; Park & Jang, 2016; Sohn & Lim, 2020). Korean speakers' difficulties involve both perceptual and production aspects of /r/ and /l/. They are hard to distinguish in perception because they are not contrastive sounds in Korean. L2 phones that correspond to a single category in L1 are hard to differentiate (Flege, 1987). In production, Korean /l/ is not velarized in word-final position (Iverson & Sohn, 1994), so Korean has articulatory difficulties in the production of English dark /l/.
The difficulties are closely related to the phonological context where they appear. According to the corpus-based study of Kim & Rhee (2019), in word-final position, a single coda /r/ was more accurately pronounced than a single coda /l/ (car vs. all). In English, /l/ is velarized in word-final position (Gimson, 1989; Ladefoged & Johnson, 2011), which is difficult for Korean learners to produce (Jang, 2005).
Few studies focused on the production of the /rl/ cluster. Kwon (2010) examined the production of the /rl/ sequences in English words girl and early by Korean and English speakers. The comparison of formant transition slopes shows that the slope was significantly different in Korean vs. English speakers in all three formants (F1, F2, F3) in the production of girl. On the other hand, for early, F2 does not show a significant difference between Korean and English speakers, where the /l/ is a syllable onset.
The production of American /r/ is highly variable depending on context and speaker, ranging between the two extreme ends: bunched or retroflexed /r/ (Delattre & Freeman, 1968; Guenther et al., 1999; Hwang, 2021; Zhou et al., 2008). Despite large variations in articulation, the acoustic characteristic is relatively simple, a "deep dip" in F3 (Espy-Wilson, 1992; Feng, 2020; Guenther et al., 1999; Idemaru & Holt, 2013; Johnson, 2003; Ladefoged & Maddieson, 1996). The low F3 for /r/ is due to the resonance from the anterior cavities formed by the palatal constriction (Stevens, 1998) and lip rounding (Delattre & Freeman, 1968). The acoustic stability of F3 is maintained by the tradeoff relationships between the length of the front cavity and the length and size of the palatal cavity (Guenther et al., 1999:13).
The alveolar lateral approximant /l/ has two allophones, light [l] in syllable onset position and dark [ɫ] in syllable coda position in English (Carr, 2020; Gimson, 1989; Ladefoged & Johnson, 2011). In the articulation of dark or velarized /l/, the front of the tongue is pushed down while maintaining the alveolar contact, and at the same time, the back of the tongue is raised toward the dorsum. F1 increases as the tongue body is lowered, while F2 decreases as the tongue-dorsum retracts. As a result, F2-F1 values decrease for dark /l/ (Ladefoged & Johnson, 2011; Sproat & Fujimura, 1993; Stevens, 1998; Sohn & Lim, 2020). Darkness of /l/, or the degree of velarization, is gradient, depending on boundary strength, so /l/ is more velarized in word-final position than in intervocalic or post-boundary position (Sohn & Lim, 2020).
To summarize, the acoustic correlate of /r/ is F3 and the acoustic correlate of dark /l/ is F2-F1. Thus, in the present study, these two acoustic measures are collected to examine the production of /rl/ sequences.
The DTW algorithm is an algorithm to compare time-series data that change over time (Giorgino, 2009; Sakoe & Chiba, 1978). The algorithm is widely used in various fields, such as speech recognition, econometrics, and other general time-series mining. Acoustic measures, such as F0 and formant frequencies, are also time-series data, so DTW can be used to compare two sets of acoustic data. The DTW algorithm compares a pair of temporal data of different lengths by stretching or compressing them to make them match each other as much as possible. The algorithm finds the best matching points of two sounds in a way that minimizes the summed cost of differences. The matching of two sounds is not based on the same-interval time-step but based on the series of the points whose summed differences are the smallest, or the optimal path. Therefore, the DTW algorithm can deal with two sets of data of different lengths. The differences computed from the optimal path are summed. The total difference or the remaining cumulative distance is the phonetic distance of two compared sounds, expressed in a single numerical value. The greater the distance, the more different the two sounds are.
The DTW algorithm was used in Cho et al. (2021) to measure the phonetic distance between two words. They measured phonetic distances in the Mel-frequency cepstral coefficients (MFCC) values. In the present study, I use the DTW algorithm for formant comparison (F2-F1 and F3, the acoustic correlates of /r/ and /l/ mentioned in Section 1.2.). The DTW algorithm has been applied to formant data in the literature (Boujnah et al., 2021; Kasuya et al., 1994; Regier, 2014).
The DTW algorithm is appropriate for the study of spoken words because they have different durations when produced by different speakers and even when produced by the same speakers. Moreover, it can capture the dynamic characteristics of formants that change over time. Most previous research has depended on some selected subsets of formant measures, such as formant values at static time points, formant differences, or formant transition slopes between two time-points (e.g., Kwon, 2010; Park & Jang, 2016; Sohn & Lim, 2020). These measures may not fully capture the characteristics of formant trajectories that change over time. The DTW method compares the formant contours as a whole, finding the optimal matching points between two data sets.
2. Research Methods
The speakers were 4 native speakers of American English (E1, E2, E3, E4) and 4 Korean speakers (K1, K2, K3, K4). The American speakers had rhotic accents (three midwestern, one western) and they were in their late 20's to late 30's. The Korean speakers were in their 20's with high-intermediate English proficiency (TOEIC scores 795−900). All the subjects were compensated for their participation.
The words containing the /rl/ sequence, pearl and world, were compared with bird and word that have the same place of articulation in word-initial position but a sequence /rd/ in word-final position. The words were embedded in a carrier sentence, "I said __ today."
Table 1 shows the target words. The place of articulation of the word-initial segments was controlled in each pair, (a) (labial) and (b) (labial-dorsal). In each pair, final sounds were different, /rl/ vs. /rd/. World has an additional /d/, but it was included for comparison with word, which is minimally different by /l/.
| Word | IPA | POA (initial) | Final sounds |
|---|---|---|---|
| (a) pearl | [pɜ:ɹl] | lab | rl |
| bird | [bɜ:ɹd] | lab | rd |
| (b)world | [wɜ:ɹld] | lab-dor | rld |
| word | [wɜ:ɹd] | lab-dor | rd |
The Korean speakers were recorded in a sound-attenuated recording studio in a university. The sampling frequency was 44.1 kHz, with a sample size of 16 bits. The English speakers were recorded online using an online recorder, Vocaroo (http://vocaroo.com), due to the pandemic. They were asked to read the sentences in a quiet room. The subjects were given a list of sentences in randomized order and asked to read the list three times in a quiet room.
For each speaker, there were 12 tokens (4 words×3 repetitions). The words recorded by English speakers were all pairwise compared with those recorded by Korean speakers [(12 tokens by an English speaker×12 tokens by a Korean speaker)×4 Korean speakers=576 pairs]. The pairs included all possible combinations between English (E1−E4) speakers and Korean speakers (K1−K4) (e.g. E1-K1, E1-K2, E1-K3, E1-K4 for speaker E1). The words recorded by English speakers were also compared by those recorded by the same group of English speakers [(12 tokens by an English speaker×12 tokens by another English speaker)×4 English speakers= 576 pairs]. For example, English speaker E1's tokens were pairwise compared with the tokens by English speaker E1, E2, E3, E4 in turn. From here, pairs with identical sounds [same tokens by the same speaker, 48 in total (4 words×3 repetitions×4 speakers)] were excluded. Thus there were a total of 1,104 pairs. The DTW distances were computed for each of these pairs. The differences are compared in terms of (i) formants and (ii) similarity distances measured by DTW. The details are explained in the next two sections.
Formants (F1, F2, F3) were automatically collected using a Praat script. The formant values were collected at three points, the beginning, middle, and end of the voiced interval (the vowel and /r(l)/) in each word. Some speakers optionally released word-final obstruent /d/ (bird, world, word). The optional closure and release for the final /d/ were excluded in the analysis.
The DTW algorithm was used to measure the similarity between the words produced by Korean and English speakers. The codes for DTW were created in Python in Google Colaboratory.1 The dtw-python library (Giorgino, 2009) was used to implement the DTW algorithm. The praat functions in the package parselmouth (Boersma & Weenink, 2020; Jadoul et al., 2018) were used to automatically extract formant values in the Python environment,2 and the os.walk function in the package os was used to loop through the sound files in Google Drive.
F2-F1 and F3 values were collected for each word from the midpoint to the end of the voiced portion (vowel and /r(l)/) of the word, i.e., the second half of the rime excluding /d/. The first half of the rime was excluded to avoid the effect of the onset consonant. It is difficult to reliably segment vowels and /r/ because vowels are rhotacized before /r/ (Allen, 1979; Celce-Murcia et al., 2010:217; Chung & Pollock, 2014). The acoustic correlates of r-colored vowels and /r/ are both F3. Thus, instead of segmenting the vowel and following /r/, the second half of the rime excluding /d/ was used for similarity analysis.
The F2-F1 and F3 trajectories were compared for each pair of words using DTW. The distance in each pair is expressed by a single numerical number (DTW distance). As explained in Section 2.2.1., there were 1,104 pairs, so a total of 1,104 DTW distance values for F2-F1 and a total of 1,104 DTW distance values for F3 were obtained. Formant values and DTW distances were visualized and analyzed using R (version 4.1.2) (R Core Team, 2021).
Firstly, it is expected that DTW distances between the words produced by English speakers and the words produced by Korean speakers (between-language distances) will be greater than those between the words produced by English speakers (within-language distances). Secondly, assuming the /rl/ sequence is hard for Korean speakers to pronounce than /rd/, it is expected that the DTW distance between Korean and English speakers will be greater in /rl/ clusters than in /rd/ clusters.
3. Results
Figures 1 through 4 show the changes of the formants at three points (beginning, middle, end) in words produced by English and Korean speakers. In all figures, there is a deep dip in F3 values in the middle of the word in both English and Korean speakers, which is an acoustic characteristic for /r/ (Ladefoged & Maddieson, 1996). On the other hand, F2 shows different patterns depending on speaker L1. In Figure 1, whereas English speakers' F2 does not much change from the mid to the end of the word (with wide variation), Korean speakers' F2 substantially increases toward the end of the word. F2 is lowered by a dorsal constriction that is required syllable-final dark /l/ (Johnson, 2003:163), so this means that Korean speakers did not have a dorsal constriction for dark /l/. In brief, the trajectories in Figure 1 show that Korean speakers had the articulatory gestures for /r/ but not for dark /l/ in the production of pearl.




On the other hand, in bird (Figure 2), both F2 and F3 gradually increase from the midpoint to the end of the word, in both English and Korean speakers. We can see that the difference between F1 and F2 (F2-F1) becomes greater toward the end of the word in both groups, which is expected due to the absence of /l/ in bird.
Similar patterns are found in world vs. word in Figures 3 and 4. In world (Figure 3a) by English speakers, F3 is lowered and then increases, suggesting the production of /r/. F2 slightly decreases toward the end of the word, and F2 and F1 get closer to each other (i.e., smaller F2-F1), suggesting the production of [ɫ]. In contrast, in the same word produced by Korean speakers (Figure 3b), there is a dip in F3, suggesting the presence of /r/, but the difference between F2 and F1 becomes greater toward the end of the word, suggesting the absence of [ɫ].
On the other hand, in Figure 4 for word, the patterns of F3 and F2-F1 are similar to each other in English and Korean speakers. There is a dip in F3 for the articulation of /r/, and the difference between F2 and F1 increases toward the end of the word in both speaker groups.
In summary, the words world and word are distinguished by F2 by English speakers, comparing Figures 3a and 4a. However, the two words are not differentiated by Korean speakers. The formant trajectories are not much different in Figures 3b and 4b. The same applies to Figures 1 and 2.
Figures 5 and 6 each show examples of two trajectories aligned by the DTW algorithm. The solid lines are the trajectories of formant values over time. The dotted straight lines connect two points in each trajectory, which are the optimal path that minimizes the distance between the trajectories.
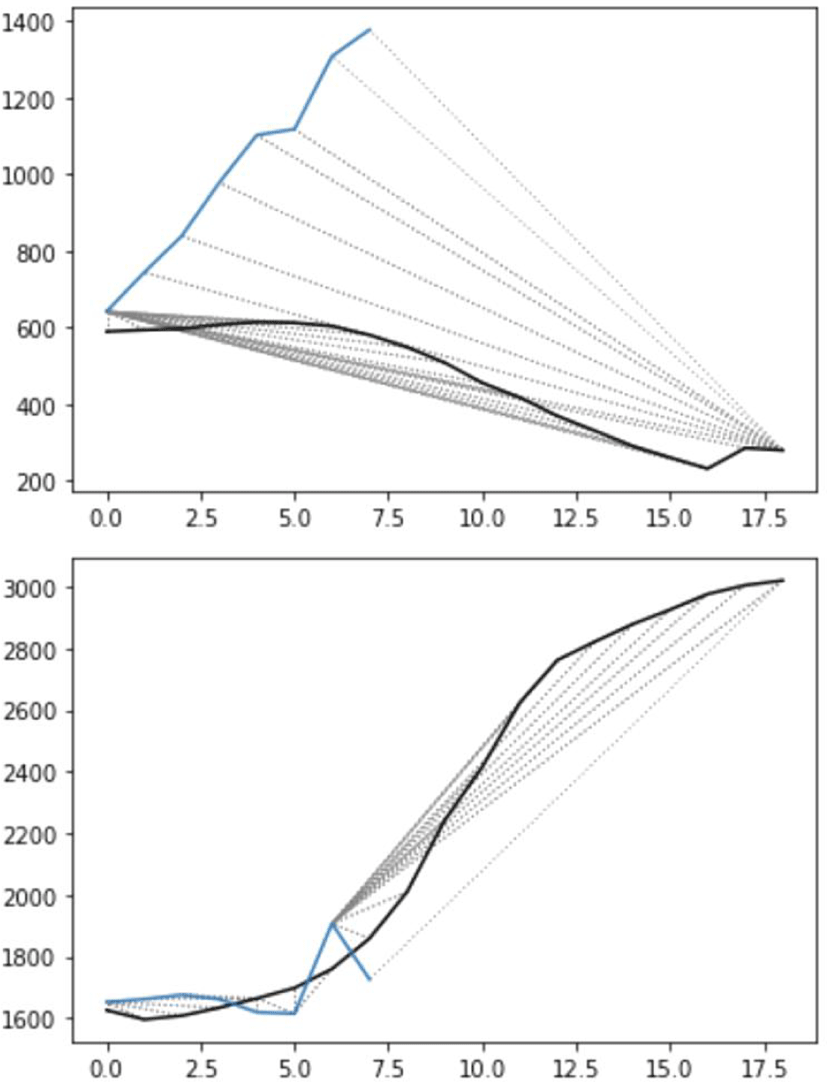
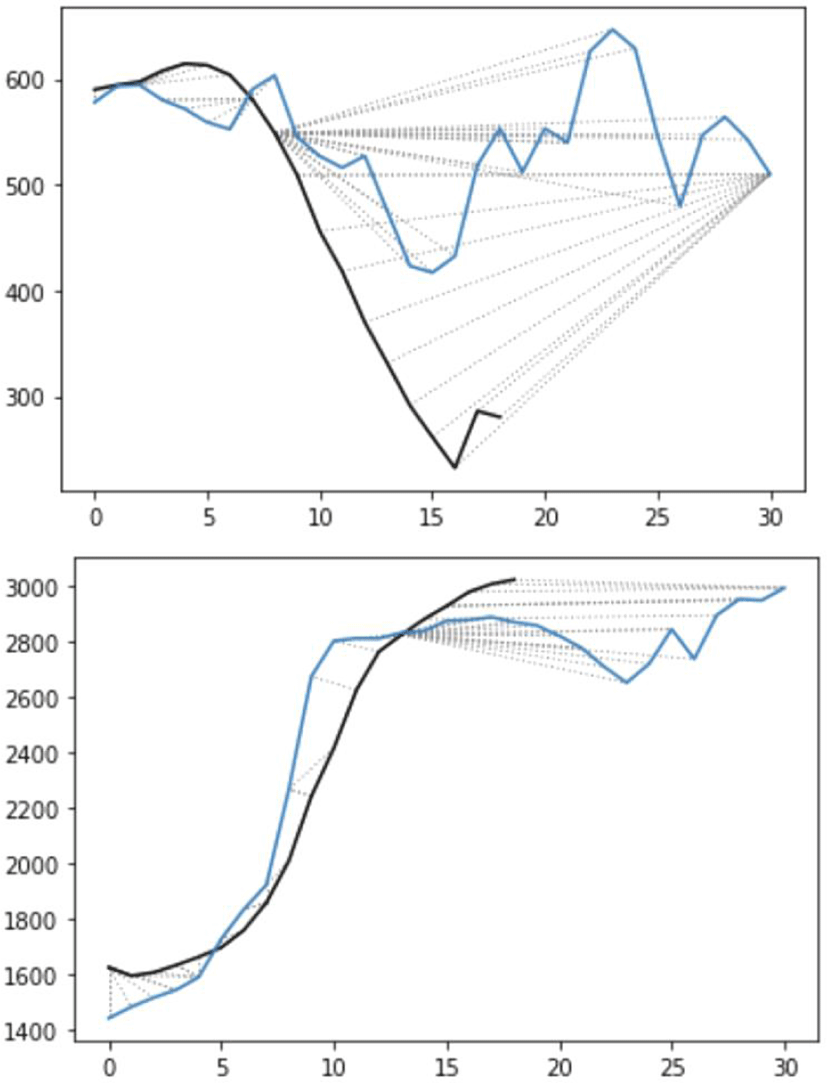
Figure 5 shows an example of how the formant trajectories of English and Korean speakers are aligned (black: English, blue: Korean). The plot at the top shows the alignment between F2-F1 values, which decrease over time for the English speaker but increase for the Korean speaker. Given that dark /l/ has low F2-F1, this shows that the English speaker produced dark /l/ toward the end of the word but the Korean speaker did not. The plot at the bottom shows the alignment of F3 trajectories between the Korean and English speakers. Both trajectories tend to increase toward the end. It is also noticeable that the DTW algorithm can compare the words with different durations as shown here (Korean: about 7.5 ms, English: about 17.5 ms). The DTW distances are 330 in the top panel and 391 in the bottom panel, which means that in the illustrated example, F3 trajectories are more different from each other than F2-F1 trajectories.
On the other hand, English speakers are more similar to each other in F2-F1 as well as in F3. Figure 6 illustrates the alignment of F2-F1 (top) and F3 trajectories (bottom) of two tokens of world each produced by English speakers (E3: black, E4: blue). In the top panel, the black line is the F2-F1 trajectory of speaker E3, and the blue line is that of speaker E4. Though E3 and E4 have individual differences, both lines show decreasing trends. Individual variations are also observed in F2 values in Figure 3a, so individual variations are expected in F2-F1 values as well. E3's trajectory drastically decreases over time. On the other hand, E4's trajectory has perturbations, but a descending trend can be found, looking at the beginning and endpoints of the trajectory.
The plot at the bottom shows the alignment of F3 trajectories for the two English speakers, which are similar to each other. The DTW distances are 56 in the top panel and 47 in the bottom panel, which means that in the illustrated example, F2-F1 trajectories are more different each other than F3 trajectories. Compared with examples in Figure 5, the DTW distances between English speakers are much lower than those between English and Korean speakers despite perturbations in formant trajectories. Thus, we can see that the DTW algorithm can capture overall trends despite local perturbations.
Mixed-effects linear regression models were fitted to the data with DTW distances as a dependent variable, formants (F2-F1, F3 separately), and the speaker group that is compared with the English speakers (L1 English or Korean) as fixed effects. Random intercepts for two speaker groups separately were included.
Figure 7 shows the DTW distances in F2-F1 for the within-language pairs (English-English) (light-grey boxes) and the between-language pairs (English-Korean) (dark-grey boxes). As expected, the between-language distances are greater than the within-language distances. This means that the F2-F1 values are more similar to each other among English speakers when compared with Korean speakers. It is also noticeable that in the English-Korean pairs, the DTW distances of pearl, world are greater than those of bird, word. That is, the Korean speakers are more different from the English speakers in the production of the /rl/ cluster than the /rd/ cluster.

A mixed-effects linear regression analysis shows that the differences are all significant (Table 2). In the production of the /rl/ and /rd/ clusters, Korean speakers are significantly different from English speakers [t(8.05)=6.33, p<.001]. The positive coefficient value (B=61.06) indicates that the DTW distance is greater in English-Korean pairs than in English-English pairs. The /rl/ and /rd/ clusters were also significantly different in L2-L1 values [t(1,091)=2.84, p<.01], due to the presence and absence of dark /l/. The positive coefficient value (B=14.64) indicates that the DTW distance is greater when the coda is /rl/ than /rd/. This indicates that the production of /rl/ varies more than /rd/ in English as well as Korean speakers. The interaction of L1 and coda was also significant [t(1,091)=2.67, p<.01], with a positive coefficient (B=19.05). This means that the DTW distance is greater in English-Korean pairs and when the coda is /rl/. That is, Korean speakers produced /rl/ words differently from English speakers, and the difference is significantly greater compared with /rd/ words. The standardized coefficient (β) shows that the language effect is greater than the coda effect. That is, the between-language distances are greater than the differences due to coda.
| B | β | SE | df | t-value | p-value | |
|---|---|---|---|---|---|---|
| Intercept | 76.08 | 8.33 | 9.89 | 9.13 | <.0001 | |
| L1:KOR | 61.06 | .43 | 9.64 | 8.05 | 6.33 | <.001 |
| Coda:rl | 14.64 | .10 | 5.14 | 1,091 | 2.84 | <.01 |
| L1:KOR×Coda:rl | 19.05 | .12 | 7.13 | 1,091 | 2.67 | <.01 |
Figure 8 shows the DTW distances in F3 for the within-language pairs (English-English) (light-grey boxes) and the between-language pairs (English-Korean) (dark-grey boxes). For each word, the distance is greater when the compared speaker's L1 is Korean. It can also be seen that the DTW distances of the /rl/ cluster are greater than the /rd/ cluster. That is, for English-Korean pairs (dark-grey), the DTW distances are greater in pearl than in bird, and in world than in word. Pearl and bird look also different in English-English pairs (light-grey), so there seem great deviations among English speakers with the word pearl.

The result of mixed-effects linear regression is shown in Table 3. The between-language differences were significant [(t(6.71)=3.14, p<.05]. This means that English speakers are more similar to each other than English vs. Korean speakers in F3. The positive coefficient value (B=82.14) indicates that the DTW distance is greater in Korean-English pairs than English-English pairs. The coda effect (/rl/ or /rd/) is also significant [t(1,090)=5.8, p<.0001]. The positive coefficient value (B=45.10) indicates that the DTW distance is greater for /rl/ than /rd/. However, the interaction term suggests that the F3 for the /rl/ cluster is not particularly different in the English-Korean pairs [t(1,090)=−.27, p=.787]. This indicates that both speaker groups have similar F3 trajectories, suggesting that the Korean speakers' /r/ production was similar to the English speakers' /r/ production at least for these words.3
| B | β | SE | df | t-value | p-value | |
|---|---|---|---|---|---|---|
| Intercept | 118.62 | 20.07 | 8.49 | 5.91 | <.001 | |
| L1:KOR | 82.14 | .36 | 26.19 | 6.71 | 3.14 | <.05 |
| Coda:rl | 45.10 | .20 | 8.71 | 1,090 | 5.18 | <.0001 |
| L1:KOR×Coda:rl | −3.26 | −.01 | 12.05 | 1,090 | −.27 | .787 |
4. Discussion and Conclusion
The present study examines the phonetic realization of word-final /rl/ sequences by English vs. Korean speakers. The word-final /rl/ cluster poses a challenge for Korean speakers because it is a sequence of two sounds that are not contrastive in Korean. In this paper we looked at two acoustic correlates of the /rl/ sequence: F2-F1 for the presence of dark /l/ and F3 for the presence of rhoticity for /r/. The DTW distances show clear differences between English and Korean speakers' /rl/ production. A significant language- dependent difference is found with F2-F1 values. Whereas English speakers lower F2-F1 values toward the end of the word, Korean speakers do not. On the other hand, English and Korean speakers do not show significant differences in F3 trajectories. This means that when producing word-final /rl/, the Korean speakers produced /r/ relatively similar to the English speakers, but they did not produce the velarized /l/.
Unlike the previous research on Korean speakers' /r/ and /l/ production, the present study explores the use of the DTW algorithm for the direct comparison of formant trajectories. Despite temporal variations and segmental perturbations, the results indicate where the differences lie. Considering the mixed-effects results of the DTW distances, the Korean speakers produced /r/ in /rl/ clusters similarly to English /r/ but failed to produce dark /l/ in /rl/ clusters.
Note that the Korean language also has a phoneme /l/ which has the allophones [ɾ] in intervocalic position and [l] in word-final position. So in Korean, English coda /rl/ is transcribed as /l/ in loanwords, but phonetically, the Korean /l/ is not velarized. Rather, the Korean /l/ is closer to English /r/ than to English dark /l/ in terms of articulation. Korean /l/ is retroflex by some speakers, and Korean speakers' production of English /r/ is also retroflex (Hwang, 2021:368). This is further supported by error analyses in the previous studies. In coda position, the error rate of English /l/ by Korean speakers is high because dark /l/ is hard to pronounce (Park, 2004). Similarly, Kim & Rhee (2019:61) showed that single coda /r/ shows a lower error rate than single coda /l/ (69% vs. 58%).
Although the present study has limitations due to the small number of speakers and target words, it offers some initial observations. Further research is needed with more speakers and target words with various phonological environments. For example, the /rl/ clusters across syllable boundary [e.g. early [ɜ:ɹ.li] as in Kwon (2010)] can be examined using DTW. One may hypothesize that Korean speakers' earl ([ɜ:ɹɫ]) will be more different from English speakers' earl whereas Korean and English speakers' production early will be relatively more similar to each other compared to earl, because of the absence of dark /l/ in early. We can also test with different preceding vowels, such as [ɑ] (Karl). We may expect similar results if the production difficulties are due to differences in the phonemic system in L1 and L2, rather than coarticulation with preceding vowels.
The pedagogical implication is that in the production of coda /rl/, Korean learners of English should be guided to consciously make gestures for /l/ at the end of the word and not to omit it. The instruction should start with making it clear that /r/ and /l/ are two contrastive sounds in English, and both sounds in /rl/ should be separately articulated.