





1. Introduction
Many languages have a phonemic voicing contrast in strident fricatives (e.g. Tranel, 1987 for French; Shibatani, 1990 for Japanese; Ladefoged, 2006 for English; see Ladefoged & Maddieson 1996 for other languages). In contrast, Korean has the two-way phonation contrast in voiceless strident fricatives: the lenis /s/ and the fortis /s’/ which is produced on a pulmonic egressive airstream like fortis stops (e.g. /sata/ ‘to buy’; /s’ata/ ‘to be cheap’) (e.g. Kim et al., 2010b, 2011; Kim & Park 2011; H. Kim 2011). The typologically rare /s’/ vs. /s/ in Korean have received a great deal of attention in the literature (e.g. Kagaya, 1974; Hong et al., 1991; Jun et al., 1998; Cho et al., 2002; Kim et al., 2010b, 2011; Kim & Park 2011). However, the Korean fricatives have been investigated either in articulation or in acoustics/aerodynamics so far. This leads us to make simultaneous recordings of external lighting and sensing photoglottography (ePGG), in one session, intra-oral air pressure (Pio) in the other, and airflow and acoustic data in both in the present study in order to better understand the phonetic characterization of /s’/ and /s/. Beyond the scope of Korean fricatives, the present study would contribute to the simultaneous investigation of speech sounds articulatorily, aerodymanically, and acoustically in other languages as well, further deepening our understanding of speech sounds.1,2
In a recent MRI study, Kim et al. (2011) have investigated the Korean fricatives produced by two native speakers (one male and one female) of Seoul Korean, using coronal and sagittal images. What they have found is that there are two independent systematic controls during the oral constriction of the fricatives: (a) glottal opening and (b) linguopalatal constriction along the palate, concomitant with vertical laryngeal position. In both word-initial and word-medial positions, the maximum glottal opening was narrower in /s’/ than in /s/. The comparison of glottal opening in the fricatives to that of the Korean lenis (/p, t, ts, k/), aspirated (/ph, th, tsh, kh/) and fortis (/p’, t’, ts’, k’/) stops in the context /_a_a/ (Kim et al., 2005, 2010a) has revealed that the fricatives have a narrower glottal opening than the aspirated stops /ph, th, tsh, kh/ like the lenis and fortis stops both word-initially and word-medially. On the other hand, across the contexts, linguopalatal constriction is narrower in /s’/ than in /s/ at the point of maximal raising of the tongue apex while the maximal raising of the tongue blade is the same in the two fricatives; a narrow linguopalatal constriction with the tongue apex and blade is sustained longer in /s’/ than in /s/ during oral constriction; the distance between the maximally posterior point along the midsagittal tongue contour and the pharyngeal wall is longer in /s’/ than in /s/; and laryngeal height tends to be higher in /s’/ than in /s/ though vertical laryngeal positions of the two fricatives were observed to be sometimes the same in word-initial position in their female subject and also in word-medial position in their two subjects. When compared to the Korean stops, /s/ is similar to the lenis stops, and /s’/ to the fortis and aspirated stops in oral closure/constriction duration. As for the tongue apex/blade- laryngeal height coordination, Kim et al. (2011) have suggested that it is associated with the tensing of both the primary articulator (i.e. tongue apex/blade) and the vocal folds during the production of the fricatives and that this tensing is accounted for by the articulatory feature [±tense], as in the three-way phonation contrast in stops (Kim et al., 2005, 2010a). The feature [±tense] in Kim et al. (2010a, 2011) is newly modified from the traditional feature [±tense] in Jakobson et al. (1952) and C.-W. Kim (1965) according to whom the tension of the whole vocal tract is accounted for by the feature.3Kim et al. (2011) have also proposed that the other independent parameter of glottal opening is accounted for by the articulatory feature [±spread glottis] (henceforth, [±s.g.]), as in the stops, in line with Halle and Stevens (1971) with [+s.g.] for a wide glottal opening and [–s.g.] for an opening that is not wide. Thus, /s/ is specified as [–s.g., –tense] like lenis stops, and /s’/ as [–s.g., +tense] like fortis stops, as in Table 1 (a).4
| (a) | (b) | |||||
|---|---|---|---|---|---|---|
| /s/ | /s’/ | /p t ts k/ | /ph th tsh kh/ | /p’ t’ ts’ k’/ | ||
| i. | [s.g.] | – | – | – | + | – |
| ii. | [tense] | – | + | – | + | + |
In addition to the MRI studies (Kim et al., 2005, 2010a, 2011), Kim et al. (2018) have provided further experimental data in favor of the specification in Table 1 (b), using ePGG, Pio, airflow and acoustic data. From simultaneous recordings of the experimental data for the lenis /p, t, k/, aspirated /ph, th, kh/ and fortis /p’, t’, k’/ plosives, the following investigations were made: (a) the timing relations among glottal opening onset and peak, airflow onset and peak and aspiration onset in relation to acoustic events such as consonant release onset and a vowel onset; (b) how much a glottal opening peak, an airflow peak height and a Pio peak occur; (c) how much it takes to reach a Pio plateau onset from a Pio onset; (d) how long a high Pio plateau is sustained by measuring the time interval between the onset and offset of the plateau and (e) what acoustic conditions such as oral closure duration and F0 arise in accordance with the three-way phonation contrast. The investigations showed that the phasing of glottal opening and the three-way phonation contrast occurs in the order, from early to late, fortis (<) lenis < aspirated plosives, and that glottal opening peak ranges from low to high in the same order. It was also found that a Pio peak, the durations of a high Pio plateau and an oral closure, and F0 are independent of the glottal opening mechanism, varying in the order of lenis < aspirated, fortis plosives. The time to reach a Pio plateau onset also revealed that the aspirated and fortis plosives take a shorter time to reach the plateau onset than the lenis plosives. Based on the results, Kim et al. (2018) have proposed that the phonation- type-specific glottal opening is accounted for by the feature [±s.g.] and that the other phonation-type-specific pattern – a Pio peak, the durations of a high Pio plateau and an oral closure, F0 and the time to reach a Pio plateau onset – has to do with the tensing of the primary articulator and the vocal folds in the sense of Kim et al. (2010a, 2011), being accounted for by the feature [±tense], as in Table 1 (b).
The current paper seeks to do for the fricatives /s’, s/ what Kim et al. (2018) did for the plosives, namely to combine articulatory, aerodynamic, and acoustic data in a study of the phonetic characterization of the phonation contrast. Given that the Korean fricatives have been investigated either in articulation or in acoustics/aerodynamics in the literature, the simultaneous recordings should lead to a more accurate description of the fricatives. In addition, the comparison of simultaneous recordings of articulatory, aerodynamic and acoustic data for the fricatives to those for the lenis (/p, t, k/), aspirated (/ph, th, kh/) and fortis (/p’, t’, k’/) plosives in Kim et al. (2018) would strengthen our understanding of the speech mechanism of the Korean fricatives. Therefore, the simultaneous recordings in the present study should offer new insight into what acoustic and aerodynamic conditions co-occur when the two fricatives are articulatorily implemented and eventually into the phonetic characterization of the two-way phonation contrast in Korean fricatives.
Based on the findings in Kim et al. (2018), we make the following hypotheses for the fricatives /s’/ and /s/. Hypothesis 1 is that the glottis opens earlier and its peak also occurs earlier in /s’/ than in /s/ across the contexts, as in fortis vs. lenis plosives. Hypothesis 2 is that different from plosives, the two fricatives have no significant differences in glottal opening peak and airflow peak height both word-initially and word-medially, given that a large glottal opening and a high airflow peak are required in order to ensure sufficient rate of airflow for frication during the oral constriction of voiceless fricatives (e.g. Sawashima, 1969; Klatt et al., 1968; Hirose et al., 1978; Löfqvist, 1992; Lindqvist, 1972; Lisker et al., 1969; Löfqvist & Yoshioka 1984; Shadle, 2010). Hypothesis 3 is that the duration of aspiration is less context-dependent in /s’/ than in /s/, as in fortis/aspirated vs. lenis plosives. Hypothesis 4 is that the time to reach a Pio plateau onset from a Pio onset would be shorter in /s’/ than in /s/, as in fortis/aspirated vs. lenis plosives and that the time from the offset of a Pio plateau to airflow peak height would also be shorter in /s’/ both word-initially and word-medially. Hypothesis 5 is that the duration of a high Pio plateau, which is the aerodynamic counterpart of the acoustic frication duration during oral constriction of a fricative, is sustained significantly longer in /s’/ than in /s/, as in fortis/aspirated vs. lenis plosives. Hypothesis 6 is that there is no significant difference in Pio peaks between the fricatives, as among lenis, fortis and aspirated plosives, because Pio which is considered to be equal to the subglottal air pressure tends to be consistent, regardless of phonetic context (e.g. Netsell, 1969). Hypothesis 7 is that the two fricatives are distinguished by airflow resistance (R=Pio/U) at the onset and offset of a Pio plateau as well as at the time of airflow peak height, as in fortis/aspirated vs. lenis plosives.
The present study is structured as follows. Our experimental methods and results are presented in section 2 and section 3, respectively; and discussions of the results are in section 4 with a brief conclusion in section 5.
2. Methods
As test words, the two fricatives /s’, s/ were put in the contexts /_a_a/, /_ama/ and /ma_a/, as in Table 2. Among the test words, /sama/ ‘(I will) buy’ and /s’ama/ ‘(I will) wrap’ are real words with the ending suffix /ma/ used usually when old people address young Koreans, and the rest are nonsense words.
| (a) | /s’a’sa/ | /sasa/ |
| (b) | /s’ama/ /mas’a/ | /sama/ /masa/ |
Two male (M1, M2) and two female (F1, F2) native speakers of Seoul Korean participated in the present experiments, as in Kim et al (2018). The three subjects (M1, M2, F1) were in their mid-twenties and had been living in Paris for less than six months, and the subject (F2) was in her early-fifties visiting the city, when the present experiments were conducted.5 They read the test words in Table 2 and fillers embedded in the frame sentence /nɛka __ palɨmhapnita/ ‘I pronounce __’ five times at a normal speaking rate. The 120 tokens (6 test words x 5 repetitions x 4 subjects) were then analyzed.
The subjects were recorded in two sessions, with ePGG recorded in one, Pio in the other, and airflow and acoustic data in both.6 In one session where the first three authors participated, simultaneous recordings of ePGG, airflow and acoustic data were made in the soundproof recording room of the Laboratory of Phonetics and Phonology, CNRS/Sorbonne-Nouvelle (University of Paris 3). The adduction-abduction movement of the glottis during the production of the fricatives was monitored with the light source being infrared light emitting diodes (IR LEDs) placed on the exterior surface of the neck between the hyoid bone and the thyroid cartilage. Normally, two IR LEDs are placed on the sides of the larynx to illuminate the hypopharyngeal wall. This method was used for the subjects M1, M2 and F1, as shown in Figure 1 (a). However, this method cannot be used for subject F2 because she had a thick layer of subcutaneous fat. Instead, the LED light was placed on the midline neck surface to illuminate the base of the epiglottis which reduces the light transmission through the fatty tissue, as in Figure 1 (b).7 The light from the LED transmits through the neck tissues and illuminates the cavities above and inside the larynx. In turn, the light in the cavities propagates through the glottis into the lower cavity below the larynx. The strength of illumination of the sub-laryngeal region undergoes modifications of the intensity as a function of the glottal opening/closing variations. The photodiode placed on the neck surface below the cricoid cartilage (see Figure 1) detects, across the lower neck tissues, the time-varying light intensity in the sub- laryngeal region, and outputs an electric current which varies with the glottal area.
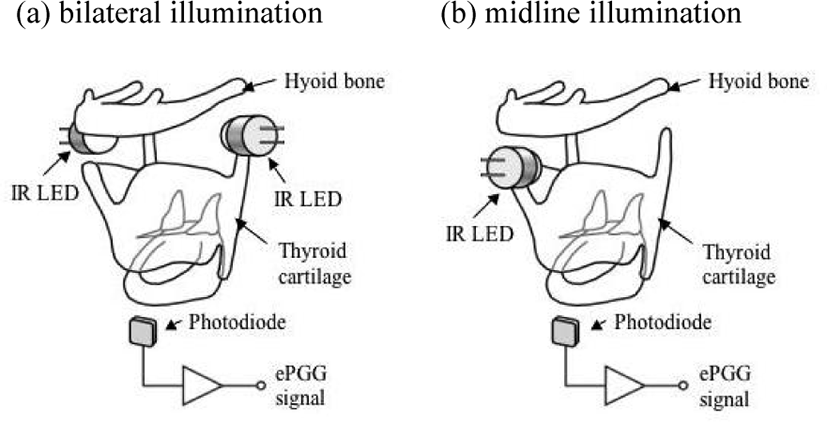
The ePGG system, which is composed of infrared LED(s) and a photodiode, forms a photo-interrupter circuit with ambient light rejection. The IR LED (810 nm, IF=100 mA) was driven by square current pulses at 16 kHz, and the incident light current on the photodiode was amplified and integrated to output ePGG signals. This ePGG technique is noninvasive and can be used with any speech material including the back vowel /a/ and voiced/voiceless consonants. Another advantage of the ePGG method is that it is possible to obtain multichannel (i.e. ePGG, airflow and acoustic) data simultaneously on natural speech from as many subjects as possible.8
Airflow rate was measured by the principle of pressure- difference anemometry using a dust-protection mask made of synthetic fibers and a differential pressure sensor. The mask’s airflow resistance was calibrated by airflow from a one-liter air syringe passing through the mask. Air pressure inside the mask was measured by a differential type of pressure sensor, PA-100-100D-W (Copal Electronics, Japan), having the range of ±10 hPa, to calculate the airflow rate in the unit of ml/sec. In addition, in order to prevent air leakage from the gap on the side of the nasal bridge when a subject’s jaw moves, an adhesive tape was used. In the other recording session where all the authors took part, simultaneous recordings of Pio, airflow and acoustic data were made in the European Hospital of George Pompidou (HEGP), Paris. Pio was measured by inserting a pressure probe to the pharyngeal cavity via the nostril with the help of our fourth author who has been a medical doctor in the hospital. The distance between the end of the probe and the glottis was around 4-5 cm. As shown in Figure 2, we used a dust-protection mask having two silicon tubes (one for air pressure and the other for airflow) connected to solid-state pressure transducers (PA-100, Copal Electronics, Japan).
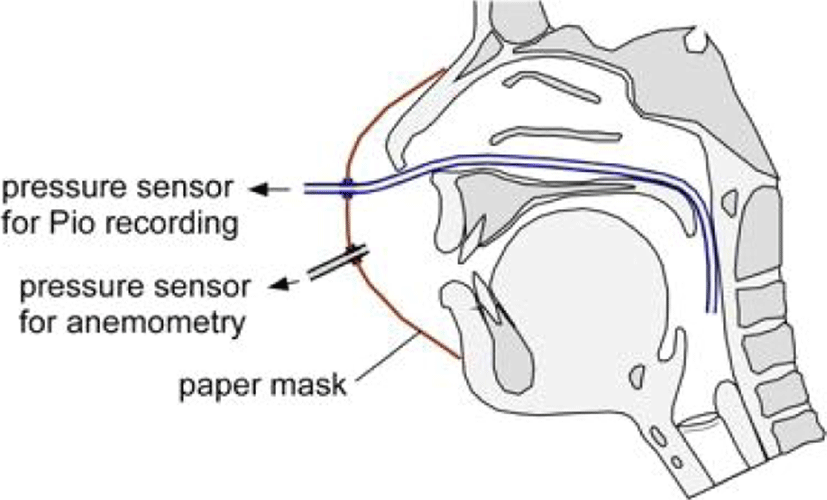
One of the transducers is highly sensitive; it, together with the mask, constitutes a Lilly type pneumotachograph. In our system, the paper-like tissue of the mask acts as an airflow resistance. Thus, when expiratory airflow passes through the mask, a small air- pressure raise occurs inside the mask due to the resistance. Conversely, inspiratory airflow causes a small drop in the air pressure. The differential transducer measures these pressure variations inside the mask relative to the outside atmospheric pressure. Our experimental study showed that the airflow resistance of individual masks is constant regardless of the practical airflow levels. However, from mask to mask variations of the resistance are rather large, even from the same lot. Therefore, we need to calibrate each mask for each subject in order to obtain a conversion scaling coefficient from voltage to, for example, liters/sec, in post- processing. We used a one-liter calibration syringe (Cardinal Health, Germany) to determine the value of the scaling coefficient of each mask before the experiment. Calibration of Pio is not necessary because the pressure sensor (Copal PA100-500D-W with the range ±50 hPa) is pre-calibrated, and the maker provides the scaling coefficient to convert the output voltage into hPa. Air pressure was recorded simultaneously with airflow and acoustic data for the fricatives in Table 2, using the same frame sentence, as in our previous data acquisition. The output signals in voltage from the transducer were converted into hPa in post-processing.
All the signals are digitally recorded at the same sampling frequency of 20 kHz with 16-bit resolution using a multichannel data recorder (Dash-8x, Astro-Med). When different sampling frequencies are assigned for different channels, the data file transfer becomes impractically slow. Because of this, we used the same sampling frequency, even though the effective bandwidth of those signals greatly varies from the narrowest, DC to 60 Hz for airflow and Pio signals to the largest, 20 Hz to 7.5 kHz for the audio signal. Table 3 summarizes the low-pass filter types, cutoff frequencies (fc) and order of analog and digital low-pass filters used in the present study.
The analog filters play the role of anti-aliasing for the digitization of signals and of bandwidth limitation to improve the noise-to-signal ratio. Here we must consider the time-delay of the analog low-pass filter, which becomes significant in the order of 10 ms, as the cutoff frequency is set as low as 60 Hz for processing airflow and Pio signals. Because the time-delay of the low-pass filter, with the cutoff frequency of 7.4 kHz, for the audio signal is negligibly small, the airflow and Pio signals are delayed by about 10 ms relative to the audio signal. We, therefore, set the cutoff frequency for these signals to 2.2 kHz. The time-delay becomes roughly 0.5 ms, which can be safely neglected in our studies. Because temporal variations of these signals are related to transitions from phoneme to phoneme and therefore slow, they can be filtered with the low cutoff frequency of 60 Hz, as indicated in Table 3. The digital filters are operated in zero-phase mode by processing the digitized signal in forward and then in backward direction in time. As the result, we have 60 Hz low-passed output signals without any additional time-delay. For the ePGG signals, we used the analog filter with DC to 5.3 kHz bandwidth to cover the syllable related slow adduction/abduction of the glottis and fast glottal oscillation during voicing, in which the filter time-delay is not the issue.
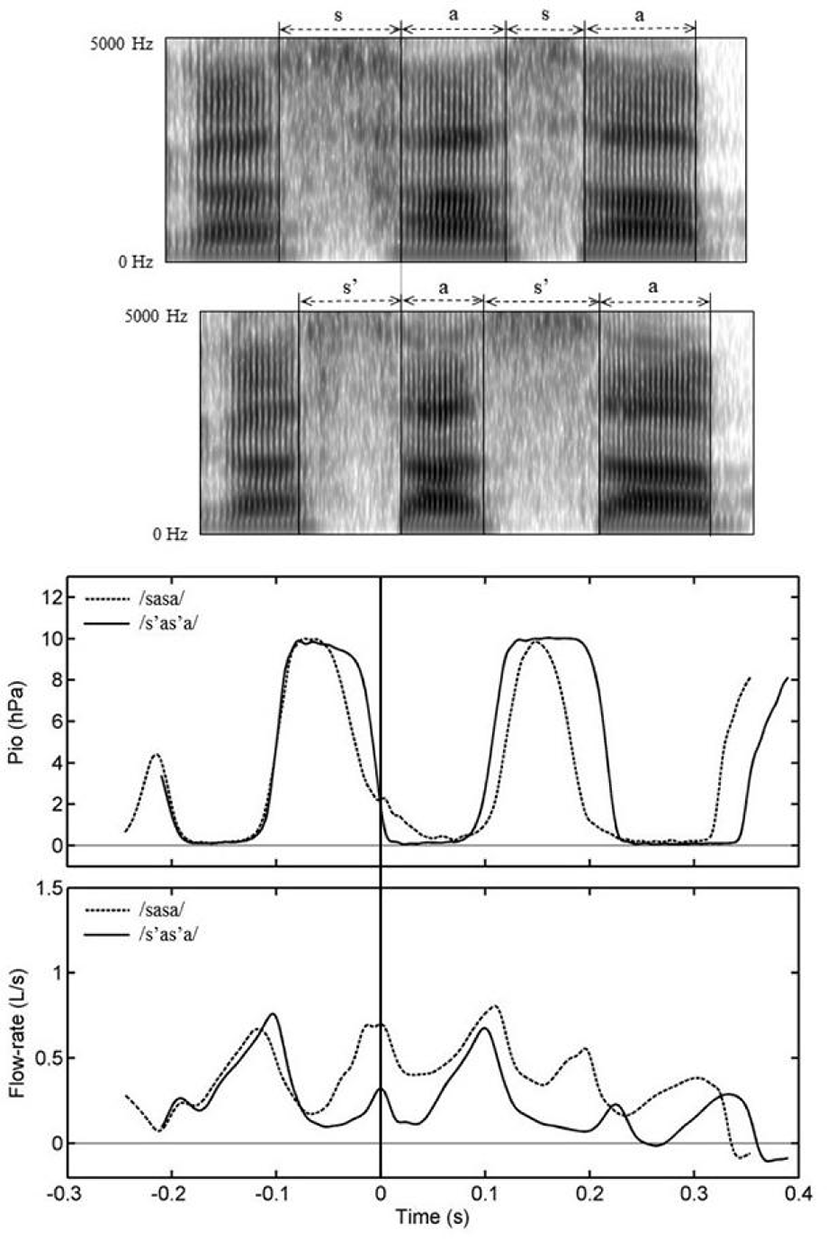
Figure 3 shows data measured on one male subject (M1), displaying, as a typical example, the wide-band spectrogram (top panel) of the acoustic signal, and the signal itself (second from top); and the ePGG and airflow signals (third and fourth from top) for the second repetition of the word /sasa/. In the ePGG signal, when the curve has a positive slope, it indicates an opening movement of the vocal folds during the oral constriction of /s/. The unit of mV in our ePGG data is an arbitrary one in that the data are not calibrated or normalized. Calibrating ePGG data is impossible, due to the fact that the morphology of the larynx and its vicinities is geometrically complex and greatly varies from one speaker to another. In addition, we have found that the properties of the tissue, which determine how light is transmitted, greatly varies depending on the subject. However, we think that the averaging of ePGG values across repetitions of the same token in the same recording session in each subject should be perfectly legitimate, though uncalibrated ePGG signals might impose a certain limitation on the quantitative data analysis.
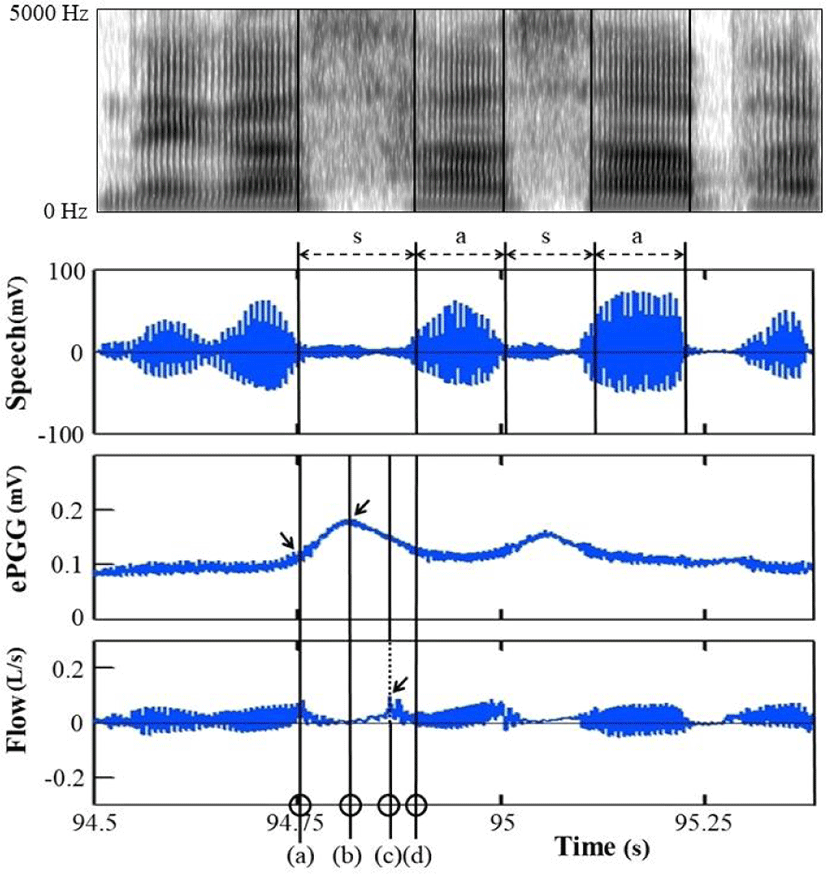
Note also that glottal opening starts in a vowel preceding the word-initial fricative /s/ in order to ensure sufficient rate of flow for frication, as reported in the literature (e.g. Klatt et al., 1968; Sawashima, 1969; Löfqvist, 1992; Löfqvist et al., 1995). To make our measurements consistent, however, we considered glottal opening occurring at the offset of a preceding vowel as its onset, as indicated by the first arrow in the third panel from top in Figure 3, with reference to a corresponding wide-band spectrogram in the top panel where the frication of the fricative starts with noise energy above 4 kHz as an alveolar fricative (e.g. Fant, 1960; Kent & Read, 2002) as well as to the signal itself (the second panel from top).
In order to investigate which fricative has the earlier glottal opening onset and peak and the longer duration of aspiration in both word-initial and word-medial positions, we referred to the time at which airflow reaches its peak as a main reference in that the frication offset of a fricative occurs at airflow peak. Given this, four temporal reference points were measured using Matlab, as marked by circles in the bottom panel in Figure 3: the time (a) at which a glottal opening onset occurs (tGOO), (b) at which a glottal opening peak occurs (tGOP), (c) at which airflow reaches its peak (tFWP) and (d) at which a following vowel starts (tVO).
Time intervals were then calculated between airflow peak and glottal opening onset, between airflow peak and glottal opening peak and between a following vowel onset and airflow peak for the three variables TGOO, TGOP and TASP for aspiration after the fricatives, respectively, as listed in Table 4.
Across all four subjects, the duration of aspiration as a transition from the offset of the frication to the onset of a following vowel was identified by noise covering a broad range of frequencies with relatively weak energy (e.g. Fant, 1960; Kent & Read, 2002) from the time point (c) to (d), compared to the frication phase of the fricative /s/ with noise energy above 4 kHz from the time point (a) to (c).
ePGG values were also measured at the time of glottal opening onset (tGOO) and at the time of glottal opening peak (tGOP), as marked by the first and second arrows, respectively, in the third panel in Figure 3, and then the former was subtracted from the latter in order to examine how high the peak of glottal opening gets during the production of the fricatives relative to glottal opening at fricative onset (GOP), as in Table 5 (a). Airflow was also measured at the time of airflow peak (tFWP) for airflow peak height (FWP), as in Table 5 (b).
| (a) GOP = value of ePGG at tGOP – value of ePGG at tGOO |
| (b) FWP = value of airflow at tFWP |
Figure 4, which is taken from the same male subject (M1), displays, as a typical example, the simultaneous recording of the acoustic, Pio and airflow data for his fourth repetition of /sasa/ in the second, third and fourth panel from top, respectively, as a function of time. Its accompanying wide-band spectrogram of /sasa/ is placed above the waveform in the top panel.
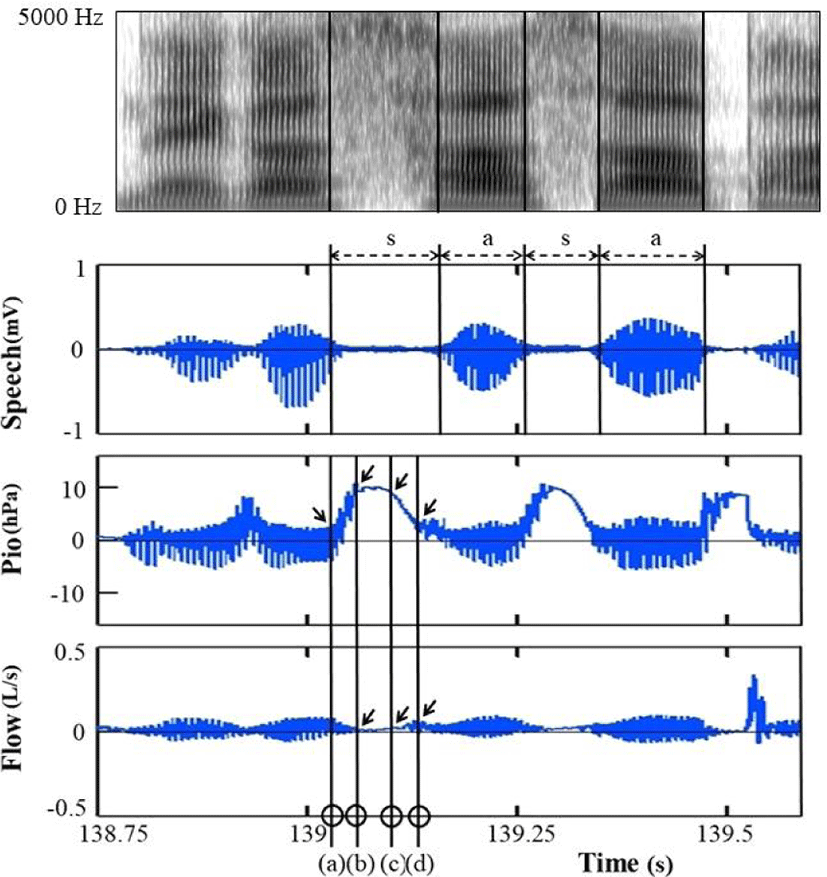
From the simultaneous recording, Pio values were measured at a Pio onset, at the onset and offset of a high Pio plateau and at the time of airflow peak height, as marked by the four arrows, respectively, in the third panel. Airflow was measured at the onset and offset of a high Pio plateau, as marked by the first two arrows in the bottom panel, respectively, and its peak height was measured after the offset of a high Pio plateau, as marked by the third arrow in the same panel. Time measurements (a) at a Pio onset (tPON), (b) at the onset (tPPON) and (c) the offset (tPPOFF) of a Pio plateau and (d) at airflow peak (tFWP) were also made, as marked by the four circles in the bottom panel, respectively.
Based on the measurements, then, we calculated time interval between a Pio plateau onset and a Pio onset (Tpp) and time interval between airflow peak and the offset of a Pio plateau (TPPFW), as in Table 6 (a) and (b), respectively, in order to examine transition time before the onset and after the offset of a Pio plateau. We also measured the duration of a Pio plateau (TPPD), deducting the time of the Pio plateau onset from that of the offset of a Pio plateau, as in Table 6 (c).
In addition, a Pio peak (PP) was measured, deducting a Pio at a Pio onset from the highest Pio during a Pio plateau, as in Table 6 (d). Airflow resistance (R=Pio/U) was calculated at the onset and offset of a Pio plateau and at the time of airflow peak height, as in Table 6 (e).9
Acoustic data recorded together with Pio and airflow data were separately stored digitally in WAV format and analyzed using Praat (Boersma, 2001; Boersma & Weenink 2019). From the acoustic data, F0 was measured at the onset of a vowel following the fricatives in both word-initial and word-medial positions.
The experimental data (i.e. ePGG, Pio, airflow and acoustic data) were measured manually by our first author after we sufficiently discussed how to measure the data over several years, and the measurement was cross-checked/verified by the others, especially by our second author who had processed all the recorded data in Matlab for measurements. For the statistical analysis of our measurements, we conducted repeated measures ANOVAs with two between subject factors (laryngeal category (i.e. /s’/ vs. /s/) and word context (i.e. /_a_a/ vs. /_ama/, /ma_a/)) and one within subject factor (word position (i.e. word-initial vs. word-medial position)). Tukey post hoc comparisons were made for the comparisons of word-initial and word-medial /s’/ vs. /s/ and word-initial vs. word-medial /s’/ and /s/.
3. Results
This section is divided into the two main subsections: one is for ePGG, airflow and acoustic data, and the other for duration of a Pio plateau, Pio peak, airflow resistance and F0.
Among the hypotheses made in the Introduction section, Hypothesis 1 was that the glottis opens earlier and that its peak also occurs earlier in /s’/ than in /s/ across the contexts, as in fortis vs. lenis plosives (Kim et al., 2018). The hypothesis is supported, as in Figure 5 where both glottal opening onset and glottal opening peak in (a) and (b), respectively, start earlier relative to the airflow peak (marked as time “0” on the vertical axis) in /s’/ than in /s/, in all four subjects, both word-initially and word-medially.10
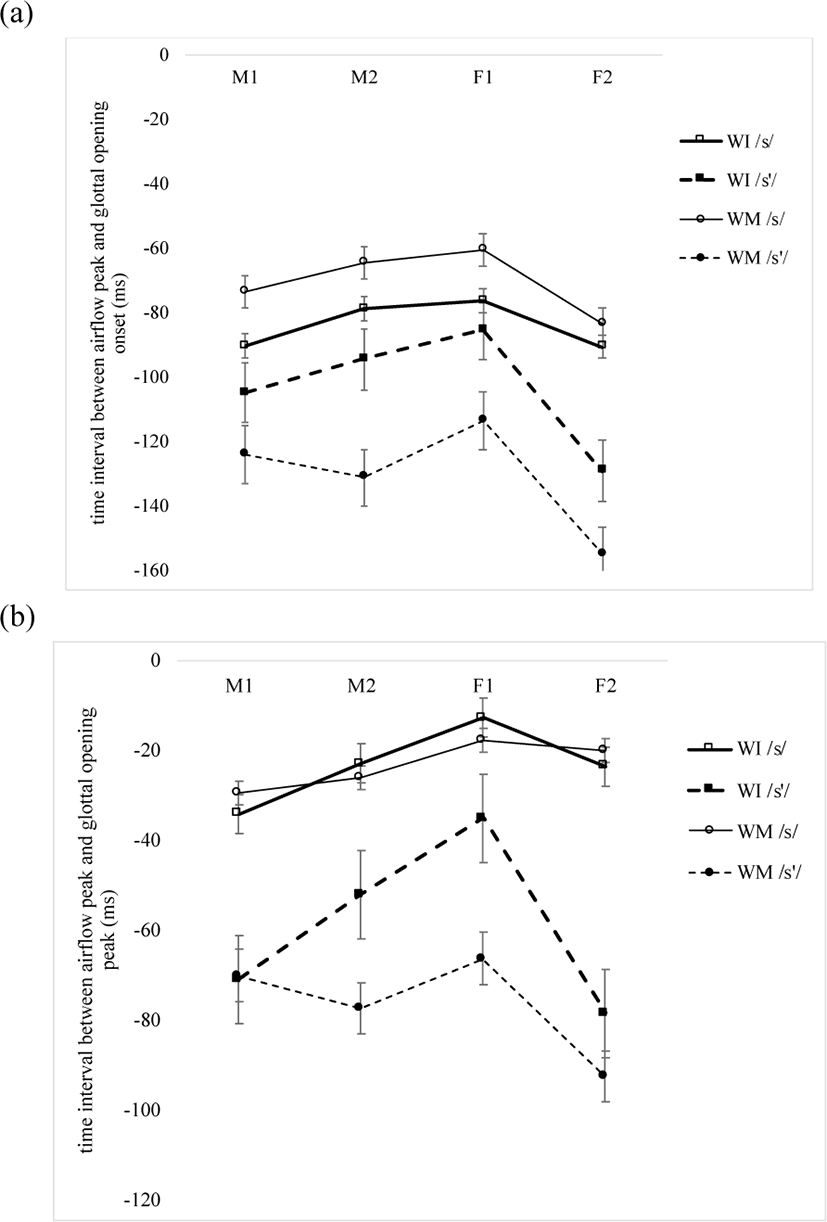
Statistical results showed that word context has no significant main effect on the time of glottal opening onset (TGOO) [F(1, 12)=0.0826, p=0.779; ɳ2p=0.007] and that the interaction of word context and laryngeal category is not significant, either [F(1, 12)=0.115, p=0.741; ɳ2p=0.009].11 Yet, there is a significant main effect of laryngeal category (i.e. /s’/ vs. /s/) [F(1, 12)=21.726, p<0.001; ɳ2p=0.644], and the interaction of word position and laryngeal category is also significant [F(1, 12)=124.9782, p<0.001; ɳ2p=0.912]. In post hoc comparisons, the time of glottal opening onset (TGOO) is not significant in word-initial /s’/ vs. /s/ [t= –1.98, p=0.243], but significant in word-medial /s’/ vs. /s/ [t= –7.09, p<0.001], whereas it is significant in word-initial vs. word-medial /s’/ [t= –10.93, p<0.001] and also in word-initial vs. word-medial /s/ [t=4.88, p=0.002]. The time of glottal opening peak (TGOP) is not affected by word context [F(1, 12)=0.775, p=0.396; ɳ2p=0.061], and the interaction of word context and laryngeal category is not significant, either [F(1, 12)=0.152, p=0.704; ɳ2p=0.012]. However, it is significantly affected by laryngeal category [F(1, 12)=51.194, p<0.001; ɳ2p=0.810], and the interaction of word position and laryngeal category is also significant [F(1, 12)=7.4216, p=0.018; ɳ2p=0.382]. In post hoc comparisons, the difference between word-initial /s’/ vs. /s/ is significant [t= –5.12413, p<0.001] and also between word-medial /s’/ vs. /s/ [t= –7.60987, p<0.001]. The difference between word-initial vs. word-medial /s’/ is significant [t= –3.86156, p=0.011], and that between word-initial vs. word- medial /s/ is not [t= –0.00887, p=1.000].
Figure 6 illustrates the average (a) glottal opening peak (GOP) of /s’/ and /s/ for the subjects M1, M2 and F1(i) and for the subject F2 (ii); and (b) airflow peak height (FWP) and (c) duration of aspiration (TASP) for all four subjects both word-initially and word-medially. Note that the scales of glottal opening peak in Figure 6 (a i) and (a ii) are different, because ePGG data were obtained for the subjects M1, M2 and F1 with two light sources on the sides of the neck, as in Figure 1 (a), and for the subject F2 with one light source at the front of the neck, as in Figure 1 (b). Therefore, a vertical scale goes up to 0.08 mV vs. 13 mV. Given the ePGG data in the present study provide information on relative glottal openings of the examined consonants, what is important is the systematic pattern of glottal opening peak among the four subjects, not the differences in the scales.
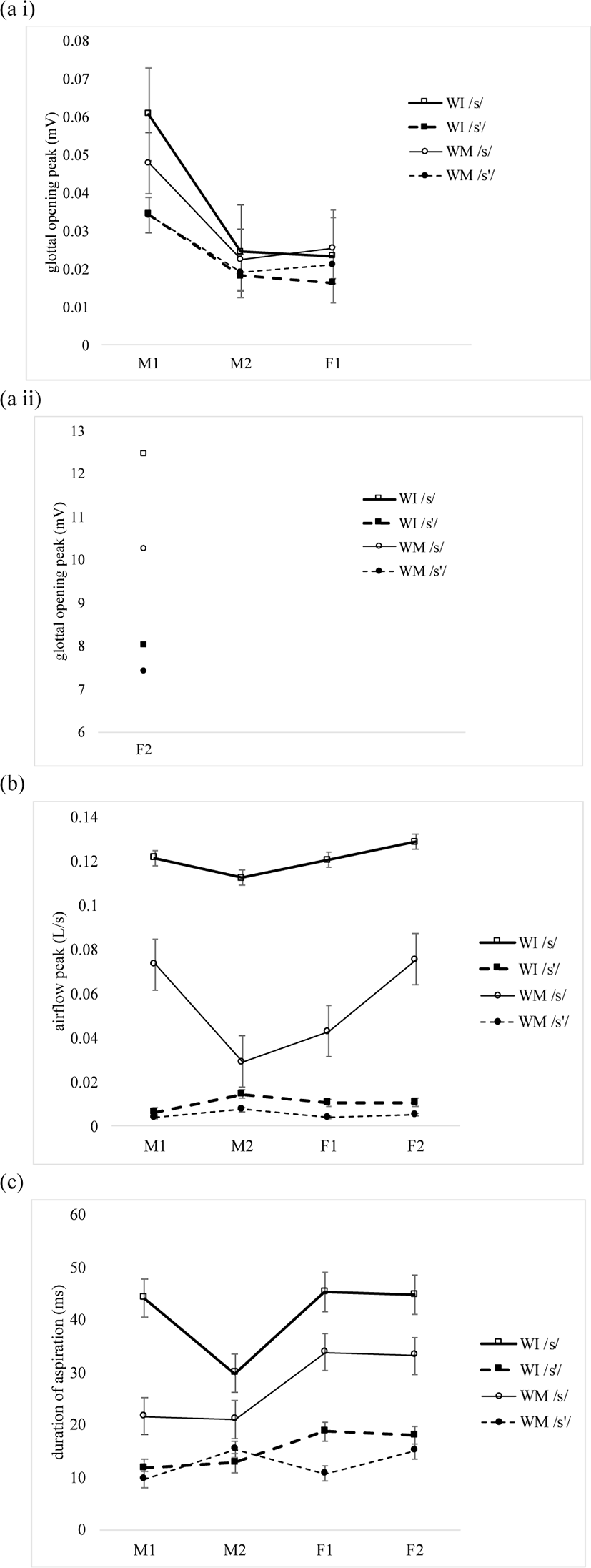
Though the peak of glottal opening is lower in /s’/ than in /s/ both word-initially and word-medially in all the subjects (Figure 6a), there is no significant main effect of word context on glottal opening peak for the subjects M1, M2 and F1 [F(1, 8)=1.021, p=0.342; ɳ2p=0.113], and the interaction of word context and laryngeal category is not significant either [F(1, 8)=0.182, p=0.681; ɳ2p= 0.022].12
In addition, laryngeal category has no significant main effect [F(1, 8)=0.504, p=0.498; ɳ2p=0.059], and the interaction of word position and laryngeal category is not significant, either [F(1, 8)=0.4826, p=0.507; ɳ2p=0.057]. In post hoc comparisons, /s’/ and /s/ are not significantly different either word-initially [t=0.9922, p=0.756] or word-medially [t=0.0635, p=1.000]. The difference between word-initial vs. word-medial /s’/ is not significant, either, in the three subjects [t= –0.1838, p=0.998], and the same is true of that between word-initial vs. word-medial /s/ [t=0.7986, p=0.853]. Airflow peak height is also lower in /s’/ than in /s/ in both word-initial and word-medial positions for all four subjects, as shown in Figure 6 (b). However, word context has no significant main effect [F(1, 12)=6.61, p=0.980; ɳ2p=0.000], and the interaction of word context and laryngeal category is not significant, either [F(1, 12)=0.00298, p=0.957; ɳ2p=0.000]. Laryngeal category has no significant main effect [F(1, 12)=1.97465, p=0.185; ɳ2p=0.141], and the interaction of word position and laryngeal category is not significant, either [F(1, 12)=2.457, p=0.143; ɳ2p=0.170]. In post hoc comparisons, /s’/ and /s/ are not significantly different, either in word-initial position [t=1.912, p=0.261] or in word-medial position [t=0.668, p=0.908]. The difference between word-initial vs. word-medial /s’/ is not significant, either [t=0.190, p=0.997], and the same is true of that between word-initial vs. word-medial /s/ [t = 2.407, p=0.129]. The statistical results support Hypothesis 2 that different from plosives (Kim et al., 2018), the two fricatives have no significant differences in glottal opening peak and airflow peak height both word-initially and word-medially.
Figure 6 (c) presents the average duration of aspiration (TASP) which is longer after /s/ than after /s’/ for all four subjects both word-initially and word-medially. There is no significant main effect of word context on the duration of aspiration [F(1, 12)=0.00214, p=0.964; ɳ2p=0.000], and the interaction of word context and laryngeal category is not significant either [F(1, 12)=0.11912, p=0.736; ɳ2p=0.010]. Yet, laryngeal category has a significant main effect [F(1, 12) = 21.12575, p<0.001; ɳ2p=0.638], and the interaction of word position and laryngeal category is also significant [F(1, 12)=11.085, p=0.006; ɳ2p=0.480]. In post hoc comparisons, the two fricatives are significantly different word- initially [t=5.672, p<0.001], but not word-medially [t=1.953, p=0.237]. In addition, the duration of aspiration is significantly reduced in word-medial /s/ [t=5.672, p<0.001], compared to that in word-initial /s/, whereas the difference between word-initial vs. word-medial /s’/ is not significant [t= –0.132, p=0.999]. This supports Hypotheses 3 that the duration of aspiration is less context-dependent in /s’/ than in /s/, as in fortis/aspirated vs. lenis plosives (Kim et al., 2018).
Figure 7 presents the alignment of the Pio and airflow data for the word-initial /s’/ and /s/ at airflow peak height after a Pio plateau in the context /_a_a/ in the fourth repetition of the subject M1. Accompanying wide-band spectrograms are aligned at the onset of a vowel following the word-initial fricatives. From the alignment of the Pio and airflow data, it is noteworthy that the slope from a Pio onset to the onset of a Pio plateau is almost overlapped in the two word-initial fricatives and that after the offset of a Pio plateau, Pio falls more sharply in /s’/ than in /s/. In addition, after the offset of a Pio plateau, airflow peak height is lower in /s’/ than in /s/ across the contexts. This gives rise to the earlier onset of a following vowel after a brief aspiration noise in /s’/ than in /s/.
The average time to reach the onset of a Pio plateau from a Pio onset (TPP) and to reach airflow peak height from the offset of the Pio plateau (TPPFW) in /s’/ and /s/ is presented in Figure 8 (a) and (b), respectively. The figure shows that it is not before the onset but after the offset of a Pio plateau that the transition time is always shorter in /s’/ than in /s/ both word-initially and word-medially in all four subjects.
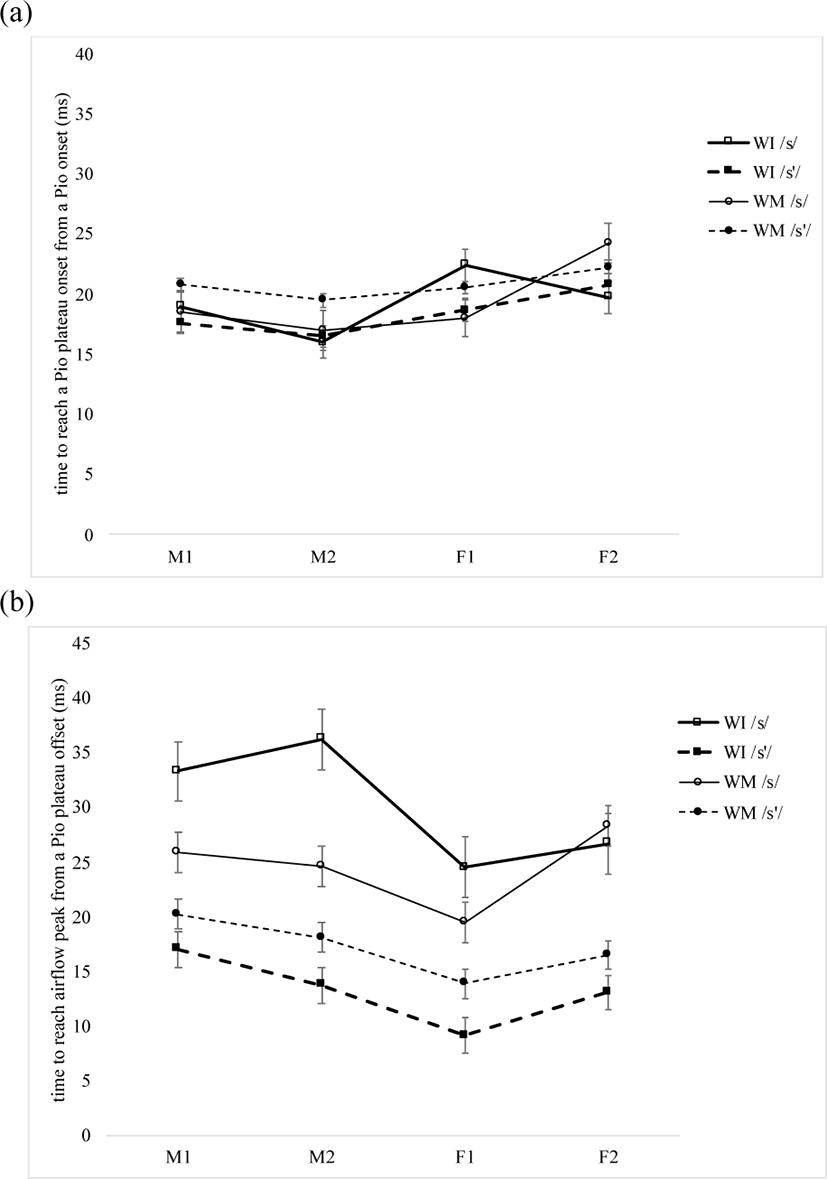
Laryngeal category has no significant main effect [F(1, 12)=1.51, p=0.242; ɳ2p=0.112], and the interaction of word position and laryngeal category is not significant, either [F(1, 12)=1.52, p=0.242; ɳ2p=0.112]. In post hoc comparisons, the two fricatives are not significantly different either word-initially [t=1.74, p=0.326] or word-medially [t= –7.98e-4, p=1]. The time from a Pio onset to the onset of a Pio plateau is significant between word-initial vs. word-medial /s’/ [t=11.55, p<0.001] and also between word-initial vs. word-medial /s/ [t=9.81, p<0.001].
As for the time from the offset of a Pio plateau to airflow peak height, it is not significantly affected by word context [F(1, 12)=0.566, p=0.466; ɳ2p=0.045], and the interaction of word context and laryngeal category is not significant either [F(1, 12)=0.00773, p=0.931; ɳ2p=0.001]. However, it is significantly affected by laryngeal category [F(1, 12)=19.81306, p<0.001; ɳ2p=0.623], and the interaction of word position and laryngeal category is also significant [F(1, 12)=5.880, p= 0.032; ɳ2p=0.329]. In post hoc comparisons, the two fricatives are significantly different word-initially [t=5.064, p<0.001], and not word-medially [t=2.559, p=0.081]. The difference between word-initial vs. word-medial /s’/ is not significant [t= –0.793, p=0.856], and that between word-initial vs. word-medial /s/ is not either [t=2.636, p=0.088 for /s/]. Given that it is after the offset of a Pio plateau that transition time is significantly different between /s’/ and /s/, Hypothesis 4 is partially supported.
Figure 9 (a) shows that the average duration of a Pio plateau (TPPD) during oral constriction is much longer in /s’/ than in /s/ at the examined contexts in all four subjects.
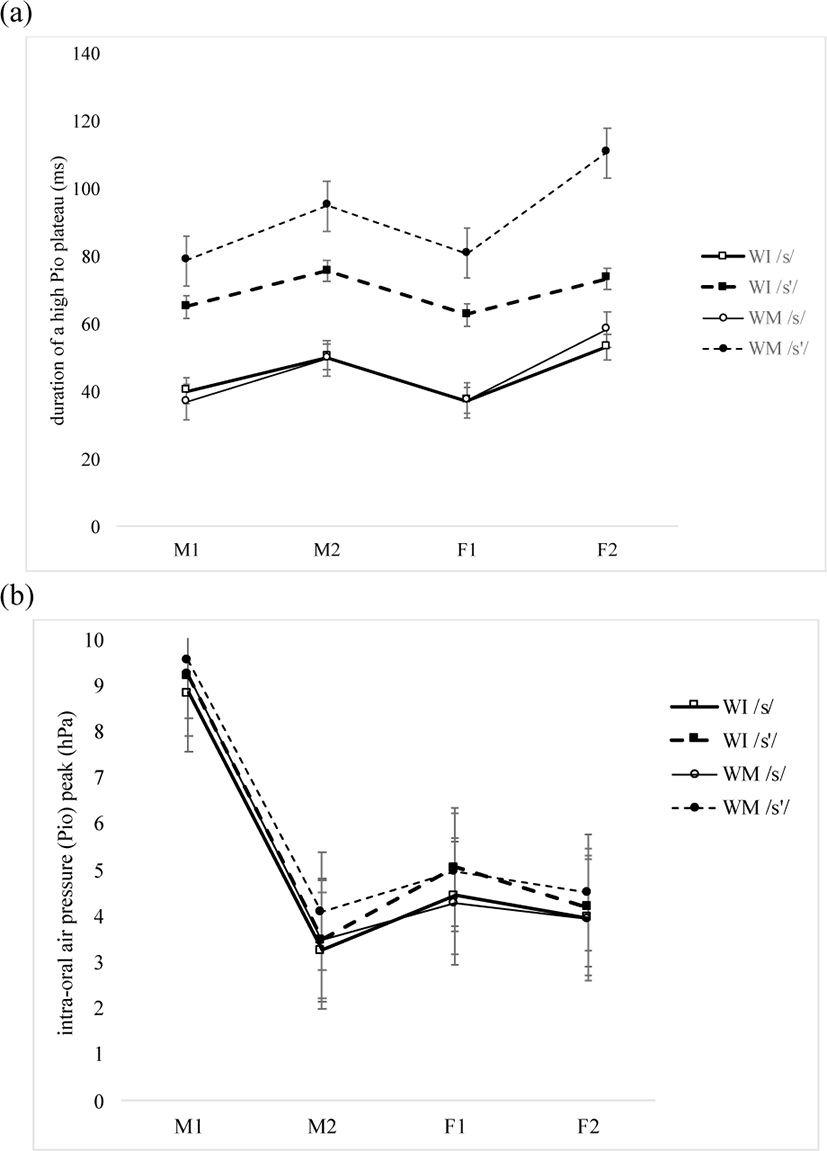
It is significantly affected by word context [F(1, 12)=7.871, p=0.016; ɳ2p=0.396], and the interaction of word context and laryngeal category is not significant [F(1, 12)=0.864, p=0.371; ɳ2p= 0.067]. Yet, laryngeal category has a significant main effect [F(1, 12)=40.224, p<0.001; ɳ2p=0.770], and the interaction of word position and laryngeal category is also significant [F(1, 12)=16.008, p=0.002; ɳ2p=0.572]. In post hoc comparisons, the difference between /s’/ and /s/ is significant, both word-initially [t= –3.9066, p=0.005] and word-medially [t= –7.4593, p<0.001]. The comparison of word-initial vs. word-medial /s/ is significant [t= –5.7322, p<0.001], but that of word-initial vs. word-medial /s’/ is not [t= –0.0739, p=1.000]. The statistical results support Hypothesis 5 that the duration of a high Pio plateau, which is the aerodynamic counterpart of the acoustic frication duration during oral constriction of a fricative, is significantly longer in /s’/ than in /s/ both word-initially and word-medially, as in fortis/aspirated vs. lenis plosives (Kim et al., 2018).
Figure 9 (b) illustrates that the average Pio peak values (PP) measured as in Table 6 (d) tend to be higher in /s’/ than in /s/ in all four subjects across the contexts.13 Word context has no significant main effect [F(1, 12)=0.17823, p=0.680; ɳ2p=0.015], and the interaction of word context and laryngeal category is not significant either [F(1, 12)=0.00460, p=0.947; ɳ2p=0.000]. In addition, there is no significant main effect of laryngeal category on Pio peak [F(1, 12)=0.05948, p=0.811; ɳ2p=0.005], and the interaction of word position and laryngeal category is not significant, either [F(1, 12)=0.0231, p=0.882; ɳ2p=0.002]. In post hoc comparisons, the two fricatives are not significantly different in Pio peak either word-initially [t= –0.224, p=0.996] or word-medially [t= –0.260, p= 0.994]. The same is true of Pio peak between word-initial vs. word-medial /s’/ [t= –0.423, p=0.973] and also between word-initial vs. word-medial /s/ [t= –0.208, p=0.997]. This supports Hypothesis 6 that there is no significant difference in Pio peaks between the fricatives, as among lenis, fortis and aspirated plosives (Kim et al., 2018), because Pio which is considered to be equal to the subglottal air pressure tends to be consistent, regardless of phonetic context (e.g. Netsell, 1969).
Figure 10 shows that the average airflow resistance at the onset and offset of a Pio plateau and at the time of airflow peak height is higher in /s’/ than in /s/ both word-initially and word-medially (see Table 6 (e) for our calculations). Airflow resistance is not affected by word context at each examined point [F(1, 12)=0.2955, p=0.597; ɳ2p=0.024 at the onset of a Pio plateau; F(1, 12)=0.103, p=0.754; ɳ2p=0.008 at the offset of a Pio plateau; F(1, 12)=0.596, p=0.455; ɳ2p=0.047 at airflow peak height]. The interaction of word contex and laryngeal position is not significant either [F(1, 12)=0.0655, p=0.802; ɳ2p=0.005 at the onset of a Pio plateau; F(1, 12)=0.166, p=0.691; ɳ2p=0.014 at the offset of a Pio plateau; F(1, 12)=0.509, p=0.489; ɳ2p=0.041 at airflow peak height].
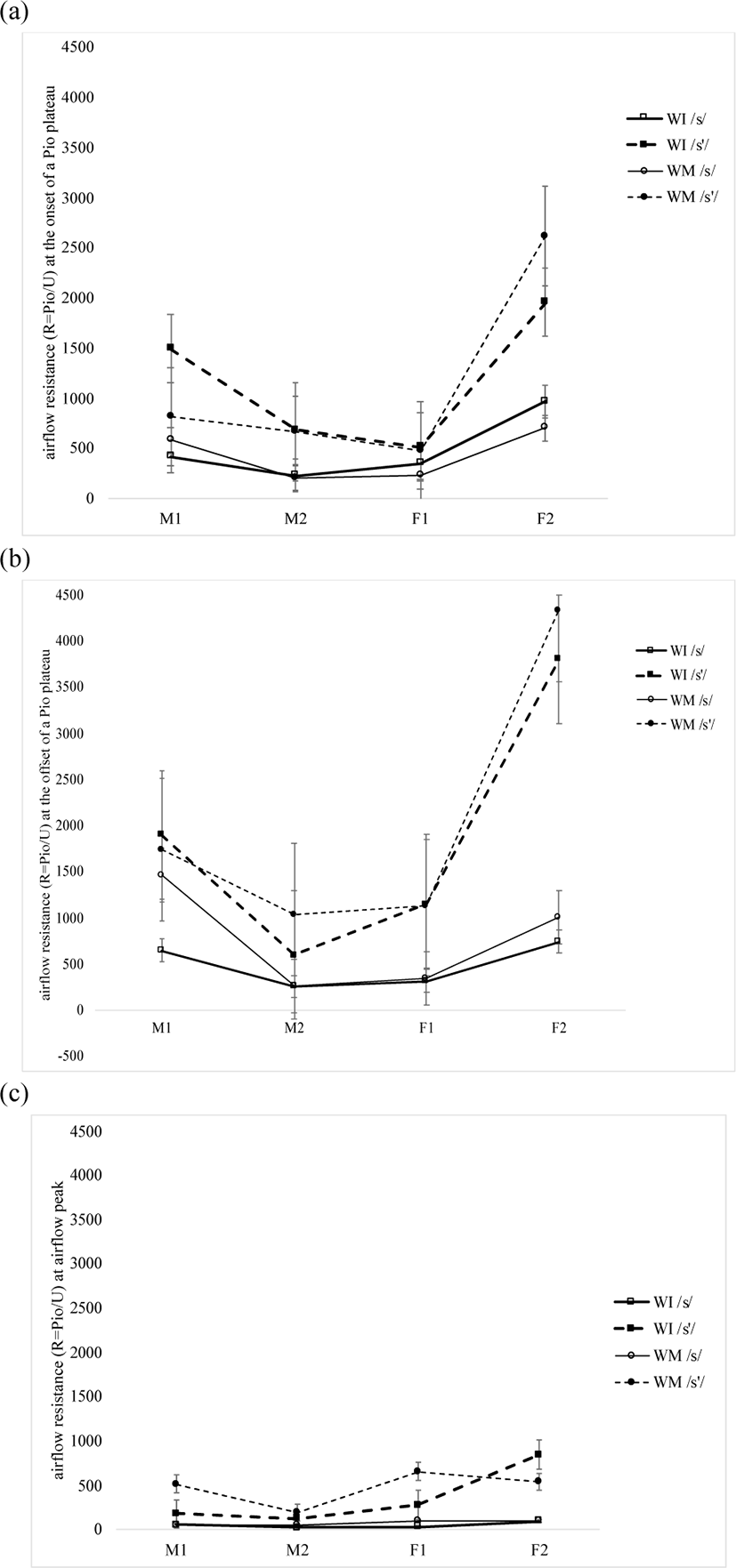
Yet, laryngeal category has a significant main effect on airflow resistance at each examined point [F(1, 12)=4.9486, p=0.046; ɳ2p=0.292 at the onset of a Pio plateau; F(1, 12)=5.908, p=0.032; ɳ2p=0.330 at the offset of a Pio plateau; F(1, 12)=17.014, p=0.001; ɳ2p=0.586 at airflow peak height]. The interaction of word position and laryngeal category is not significant at the examined points [F(1, 12)=0.0379, p=0.849; ɳ2p=0.003 at the onset of a Pio plateau; F(1, 12)=0.104, p=0.753; ɳ2p=0.009 at the offset of a Pio plateau; F(1, 12)=0.532, p=0.480; ɳ2p=0.042 at airflow peak height]. In post hoc comparisons, the difference in airflow resistance is significant between /s’/ and /s/ at airflow peak height both word-initially [t= –2.837, p=0.044] and word-medially [t= –3.722, p=0.006], not at the onset a Pio plateau [t= –2.016, p=0.225 word-initially; t= –2.152, p=0.181 word-medially] and at the offset of a Pio plateau [t= –2.44, p=0.17 word-initially; t= –2.30, p=0.1481 word-medially]. The comparison of word-initial vs. word-medial /s’/ and that of word-initial vs. word-medial /s/ are not significant, either, at the three points [t=0.113, p=0.999 for /s’/ and t=0.388, p=0.979 for /s/ at the onset of a Pio plateau; t= –1.12, p=0.684 for /s’/ and t= –1.58, p=0.427 for /s/ at the offset of a Pio plateau; t= –1.299, p=0.581 for /s’/ and t= –0.267, p=0.993 for /s/ at airflow peak height]. The significant main effect of laryngeal category on airflow resistance at the three points supports Hypothesis 7 that the two fricatives are distinguished by airflow resistance (R=Pio/U) at the onset and offset of a Pio plateau as well as at the time of airflow peak height, as in fortis/aspirated vs. lenis plosives (Kim et al., 2018).
Finally, Figure 11 shows the average F0 at the onset of a vowel following the fricatives /s’/ and /s/ across the contexts in all four subjects. The raw data for mean F0 values shows gender-related differences, as in other languages (e.g. Pinho et al., 2012). That is, average F0 values are higher in the two female subjects than in the male subjects in both of the fricatives, no matter whether they are in word-initial or in word-medial position. The gender-related differences in F0 are statistically significant [F(1, 12)=21.10849, p<0.001; ɳ2p=0.638], both word-initially [t= –4.412, p=0.004] and word-medially [t= –4.664, p=0.002]. However, there is no significant effect of word context [F(1, 12)=0.02221, p=0.884; ɳ2p=0.002], and the interaction of word context and laryngeal category is not significant either [F(1, 12)=0.00582, p=0.940; ɳ2p=0.000].
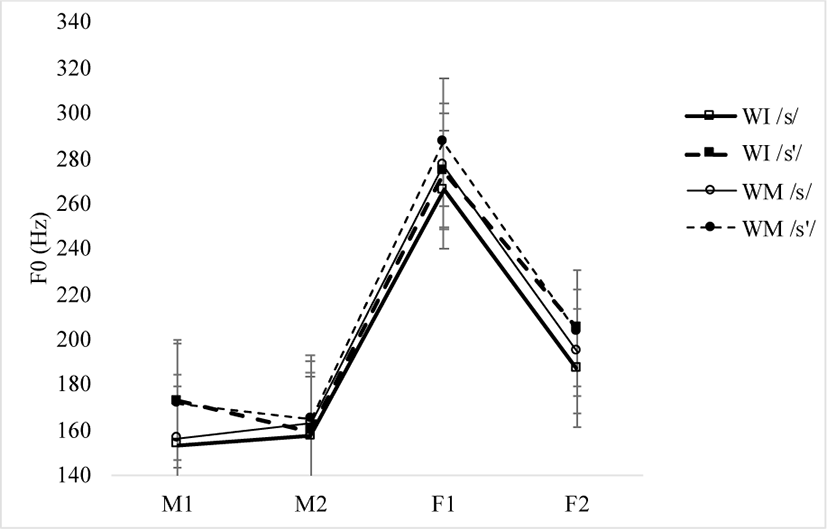
Laryngeal category has no significant main effect on F0 [F(1, 12)=0.41116, p=0.533; ɳ2p=0.033], and the interaction of word position and laryngeal category is not significant, either [F(1, 12)=0.3306, p=0.576; ɳ2p=0.027]. The comparison of the fricatives is not significant, either word-initially [t= –0.723, p=0.886] or word-medially [t= –0.543, p=0.947]. The difference between word-initial vs. word-medial /s’/ is not significant [t= –1.056, p=0.721], and the same is true of the difference between word-initial vs. word-medial /s/ [t= –1.869, p=0.291]. No significance in F0 between the fricatives either word-initially or word-medially suggests that F0 does not characterize the two-way phonation contrast in fricatives, as in the literature (e.g. Kim et al., 2010b; Kim & Park 2011).
In the next section, the results will be discussed.
4. Discussion
First, as for the statistically significant differences in the duration of a high Pio plateau and airflow resistance (Figures 9 (a) and 10), we propose that they are correlated with the tensing of the primary articulator (i.e. the tongue apex/blade) and the vocal folds, following Kim et al. (2011). In particular, among the phonetic properties related to the tensing, it is the duration of a high Pio plateau and airflow resistance that characterize the difference between the voiceless fricatives more substantially than a Pio peak and F0. That is, as a narrower linguo-palatal constriction often concomitant with a higher laryngeal raising (Kim et al., 2011) leads to a smaller oral cavity and the narrower constriction is sustained longer, a significantly longer duration of a high Pio plateau is sustained (Figure 9 (a)) with a significantly higher airflow resistance at the onset and offset of a Pio plateau and at the time of airflow peak height in /s’/ than in /s/ (Figure 10). However, a Pio peak and F0 are not significantly different across the contexts. As for the nonsignificant difference in Pio peaks, we may recall that Pio tends to be consistent, regardless of segments (e.g. Netsell, 1969). Regarding the nonsignificant difference in F0 between the fricatives (Figure 11), as in Kim et al. (2010b) and Kim and Park (2011) among others, we assume that it may be due to continuous airflow with no vocal fold vibration during oral constriction. This is reminiscent of vertical laryngeal positions which were observed to be sometimes the same in the two fricatives in Kim et al. (2011).
In addition, tenseness affects the time to reach airflow peak height from the offset of a high Pio plateau, as shown in Figure 8 (b), such that the tenser the fricative /s’/ is, the significantly shorter the time needed to reach the point of airflow peak height in both word-initial and word-medial positions. In contrast, the significantly longer transition from the offset of a Pio plateau to the point of airflow peak height after /s/ across the contexts is attributed to the laxness of /s/. The laxness of /s/ is further supported by a phonetic voicing of the fricative in word-medial intervocalic position (e.g. Cho et al., 2002; Kim et al., 2010b; Kim & Park 2011). In the acoustic data of the present study, we found no phonetic voicing of the word-medial fricative /s/ in all four subjects. Yet, for example, Kim and Park (2011) have found that among their 800 tokens with the two fricatives in both word-initial and word-medial positions, partial voicing occurred in word-medial /s/ in 113 tokens, and complete voicing throughout the fricative in 58 tokens.
Moreover, the duration of aspiration is significantly reduced in the word-medial /s/, compared to those in the word-initial /s/ and relatively consistent in /s’/ across the contexts (Figure 6 (c)). As for the significant reduction in the word-medial /s/, we suggest that it has to do with the laxness of /s/, as in lenis plosives (Kim et al., 2018). That is, it is due to the laxness of /s/ that a narrower glottal opening of the word-medial /s/ than that of the word-initial /s/ gives rise to significantly shorter duration of aspiration. In contrast, the tenseness of /s’/ results in relatively consistent duration of aspiration in both word-initial and word-medial positions. As a result, the tenseness of /s’/ is accounted for by [+tense], and the laxness of /s/ by [–tense], as in Table 1 (a ii).
Second, as for the nonsignificant differences in glottal opening peak and airflow peak both word-initially and word-medially, we suggest that the fricatives are specified as [-s.g.]. Given that glottal opening results in airflow, not the reverse, the nonsignificant difference in glottal opening peak between the fricatives empirically substantiates the view that /s/ is specified as [–s.g.] for glottal opening like /s’/, as in Table 1 (a i). One might recall that the non-fortis fricative has been proposed as aspirated (/sh/) just like aspirated plosives, especially by Kagaya (1974) among others in the literature. In his fiberscopic study, Kagaya (1974) recorded nonsense monosyllables with the fricatives /sh, s’/ and stops /p, ph, p’, t, th, t’, k, kh, k’, ts, tsh, ts’/ in the word-initial contexts /_e/ and /_i/ and in the word-medial contexts /e_e/ and /i_i/ twice in isolation from one male speaker of Seoul Korean.14 According to the fiberscopic data, the glottal opening of the non-fortis fricative at frication onset is intermediate between the lenis and aspirated stops at their oral release in the word-initial context /_e/ and similar to that of the aspirated plosives /ph, th, kh/ or wider than that of the aspirated affricate /tsh/ in the other word-initial context /_i/. However, in the word-medial contexts, “the maximum width of the glottis is about half of the maximum opening” in the word-initial contexts in the case of the non-fortis fricative (Kagaya 1974: 167), and the glottis opens much narrower in the non-fortis fricative at frication onset than in the aspirated consonants at their oral release.
If the non-fortis fricative were aspirated, its glottal opening would be consistent both word-initially and word-medially just like that of the aspirated stops, given that the glottal opening of the aspirated stops remains relatively consistent across the contexts, compared with that of the non-aspirated ones, as shown in the study. Yet, this is not the case. The maximum of glottal opening in the non-fortis fricative is much more reduced in the word-medial contexts than in the word-initial contexts, such that it is similar to that of glottal opening in the fortis fricative in word-medial position. In addition, if the non-fortis fricative were aspirated, the glottal opening of the non-fortis fricative would be wider than that of the aspirated stops both word-initially and word-medially, just as the glottis opens wider in the fortis fricative than in the fortis stops due to its frication throughout oral constriction across the contexts. However, this is not the case, either.
In contrast, what we have found is that there are no significant differences in glottal opening peak and airflow peak height between the two fricatives either word-initially or word-medially (Figure 6 (a) and (b)) and that the duration of aspiration is significantly reduced in the word-medial /s/, compared to those in the word-initial /s/ and relatively consistent in /s’/ across the contexts (Figure 6 (c)), as in lenis vs. fortis/aspirated plosives (Kim et al., 2018). The context-dependent duration of aspiration in the non-fortis fricative as well as no significant differences in glottal opening peak and airflow peak height between the two fricatives confirms that the fricative is not aspirated (/sh/) but lenis (/s/).
Finally, the context-dependent duration of aspiration in the fricative /s/ supports the view that it is prosodically accounted for as the effect of prosodic structure in an autosegmental-metrical model of intonational phonology (e.g. Pierrehumbert, 1980; Beckman & Pierrehumbert, 1986; Pierrehumbert & Beckman, 1988), as in lenis plosives (Jun, 1993, 1998, 2005a, b). For example, according to Jun (1993), the effect of prosodic position results in the difference in voicing and VOT between word-initial and word-medial lenis plosives, such that within an accentual phrase, the voicing and shorter VOT of lenis plosives do occur, whereas at the beginning of the accentual phrase the plosives are voiceless with a longer VOT. As in the lenis plosives (Kim et al., 2018; H. Kim, 2019b), the same account can be given for the difference between the word-initial and word-medial /s/ in the framework of the intonational phonology. That is, within an accentual phrase, the significantly shorter duration of aspiration occurs sometimes with a phonetic voicing in the word-medial /s/, and at the beginning of the accentual phrase, the word-initial /s/ has a longer duration of aspiration.
5. Conclusion
In order to better understand the phonetic characterization of the Korean fricatives /s’, s/ in comparison with the three-way phonation contrast in plosives (Kim et al., 2018), we have obtained simultaneous recordings of ePGG, airflow and acoustic data in one session and those of Pio, airflow and acoustic data in the other session from four (2 male and 2 female) native speakers of Seoul Korean. What we have found is that different from the plosives, the two fricatives are not significantly different in glottal opening peak and airflow peak height either word-initially or word-medially and that the duration of aspiration is significantly reduced in the word-medial /s/, compared to that in the word-initial /s/, whereas it is relatively consistent in /s’/ across the contexts, as in lenis vs. fortis/aspirated plosives. We have also found that the duration of a high Pio plateau is significantly longer in /s’/ than in /s/ both word-initially and word-medially, as in fortis/aspirated vs. lenis plosives and that airflow resistance (R=Pio/U) at the onset and offset of a Pio plateau is significantly higher in /s’/ than in /s/ as well as at the time of airflow peak height, as in fortis/aspirated vs. lenis plosives, across the contexts. In addition, we have found that the difference in Pio peak is not significant both word-initially and word-medially, as in the three-way phonation contrast in plosives, and that the two fricatives are not significantly different in F0 across the contexts, different from the plosives. It is also found that transition time to reach airflow peak height from the offset of a Pio plateau is significantly longer in /s/ than in /s’/ in both word-initial and word-medial positions.
Based on the results, we have proposed that the phonation- type-specific pattern of the duration of a high Pio plateau and airflow resistance has to do with the tensing of the primary articulator (i.e. the tongue apex/blade) and the vocal folds in line with Kim et al. (2011), being accounted for by the articulatory feature [±tense]. As a result, the laxness ([–tense]) of /s/ gives rise to the significant reduction in the duration of aspiration word- medially, whereas the tenseness ([+tense]) of /s’/ yields to a relative consistency in them both word-initially and word-medially. The laxness vs. tenseness also gives rise to a transition time difference from a Pio offset toward airflow peak height with a statistical significance. On the other hand, no statistical differences in glottal opening peak and airflow peak height lead to the confirmation that both /s’/ and /s/ are specified as [–s.g.] for glottal opening. Consequently, the present experimental data substantiate the laryngeal representations in Table 1 (a), that is, the fricative /s/ is lenis, being specified as [–s.g.] like the fortis fricative /s’/ and as [–tense] for its laxness, different from /s’/ which is specified as [+tense] for its tenseness.
To conclude, the simultaneous investigation of the Korean fricatives /s, s’/ in the articulatory, aerodymanic and acoustic aspects has revealed more phonetic properties of the fricatives compared with studies either in articulation or in acoustics/aerodynamics so far. This has eventually substantiated the laryngeal characterization of the fricatives. Given this, the present study would contribute to investigating speech sounds in articulation, aerodynamics and acoustics simultaneously in order to further deepen our understanding of speech sounds in other languages as well.