





1. Introduction
When learning the sounds of a new language, English as a foreign language (EFL) learners might encounter difficulties perceiving them, as they do not have enough speech input. The ability to identify that speech is composed of a series of individual sounds is known as phonemic awareness (Yopp, 1988). It assists learners to listen to and process foreign speech as well as connect the sounds with alphabet orthography. Segmental features, encompassing vowels and consonants, are significant matters in producing English. They are a subset of pronunciation features along with stress, pitch, fluency, and tone choices (Kang & Pickering, 2013).
L1 background is known to affect the learners’ starting points for acquiring new English phonemes (Iverson & Evans, 2009; Pruitt et al., 2006). The disparities may be due to the nature of the interaction between the sounds in the learners’ L1s and the sounds in the target languages. Previous study has found that EFL learners struggle to develop sensitivity to numerous English phonemic contrasts (Mueller, 2019). Several auditory factors separate the phonetic properties of fricatives in English and Korean. Firstly, in English, there are a total of nine fricatives which are divided into four categories based on their different articulation positions. However, in Korean, there are three fricatives and the articulation position of fricatives is only spoken in the alveolar sound (Lim & Jang, 2019). Secondly, unlike in English, where voicing contrast is a crucial auditory cue for phoneme classification, Korean has a separate mechanism for identifying phonemes, which is the aspiration (Lim & Jang, 2019). Thirdly, in English, the amplitude and length of the friction noise in the speech waveform differentiate sibilants. In Korean, the length of the friction noise serves as an auditory cue distinguishing the parasitic character of the Korean fricatives (Rhee et al., 2008). Due to these differences, English fricatives are considered to be one of the most challenging consonants for Koreans when learning English. Hence, it is critical to diagnose EFL learners’ phonemic awareness skills in order to offer information on which sounds they are likely to find difficult.
In addition, a comparison with functional loading theory would give practical recommendations on where to concentrate instructional efforts. In the same vein, the present study aims to explore Korean speakers’ perceptual confusions among some English consonants and to what extent Korean speakers are able to discriminate challenging English consonant contrasts.
2. Literature Review
Phonemic awareness is the awareness that the speech stream consists of a sequence of sounds, specially phonemes, the smallest unit of sound that makes a difference in communication (Yopp & Yopp, 2000:30). For instance, those who are phonemically aware in English can identify the three sounds in the spoken word push (/p/-/ʊ/-/ʃ/) as well as mix phonemes altogether to form words (/p/-/ʊ/-/l/ is pull). Phonemic awareness is one component of phonological awareness which is a subset of metalinguistic awareness. It can be practiced without visual information as it focuses on auditory sounds of each phoneme (Mueller, 2019). It is crucial for L2 learners to be able to comprehend what they are hearing as well as read an alphabetic orthography. Phonemic awareness education should be linked with listening training in EFL situations since learners have difficulties discerning foreign phonemes (Lee, 2021). A meta-analysis of the effect of phonemic awareness on listening comprehension in English as a second or foreign language (ESL/ EFL) explored eight articles (Choe et al., 2020). The result revealed that it is especially beneficial for beginner or younger learners. As phonemic awareness teaching has been shown to benefit elementary school students, this study includes them as a study population.
The term High Variability Phonetic Training (HVPT) first appear in research by Iverson et al. (2005), as a method for answering theoretical issues concerning the nature of second language speech learning. It refers to perceptual training, most commonly concentrating on segments, in which auditory training stimuli contain many samples produced by multiple speakers in a variety of phonetic settings (Thomson, 2018b). It evolved as a technique that can provide concentrated and high-quality experiences, resulting in demonstrable changes in the perceptual systems of late L2 learners, who had previously long been considered resistant to change, particularly after the first year of exposure (Thomson, 2018b). Logan et al. (1991) trained six Japanese listeners fifteen 40-minute HVPT sessions to distinguish English /l/ from /r/. They were substantially better at distinguishing phonemes, and this phonemic awareness could be transferred to new words as well as with new voices. Previous research investigated on the effect of HVPT and its generalizability. According to Lively et al. (1993), training with several speakers resulted in generalization to new words produced by new speakers, but training with a single speaker resulted in failure to transfer to unfamiliar words provided by the training speaker. Wong (2014) discovered that teaching Chinese speakers to distinguish English /i/-/I/ helped identifying same sounds in new contexts. Overall, the literature reports on the effect of HVPT as a training tool. The current study assesses learners’ phonemic awareness using high variability of inputs.
It is commonly accepted that infants can identify a wide range of phonetic contrasts until the age of six months (Best et al., 1988; Eimas et al., 1971). The formation of the first language (L1) speech sound inventory influences the learning of new sounds later in life, often causing difficulty in both perception and production of the foreign speech sounds (Georgiou, 2019). Flege (1987) proposed speech learning model (SLM), which states that two phonetic subsystems (L1, L2) are cognitively represented in a single phonological space and affect each other. According to SLM, new sound categories are created during L2 learning when L2 sounds differ sufficiently from L1 category. If an L2 sound is found to be similar to an existing L1 sound, the L1–L2 categories are merged. This might result in incorrect L2 speech production. The SLM suggested that as L2 learners gain experience using L2 in daily life, they will eventually discern the variations between L1 and L2 phonetics (Flege & Bohn, 2021). However, it did not offer a way to gauge how much phonetic input is required to accelerate the development of new L2 phonetic categories. The revised SLM (SLM-r) defines the phonetic input as the sensory input related to L2 speech sounds that are heard and seen during the production by others of L2 utterances in meaningful conversations (Flege & Bohn, 2021:32). Furthermore, while SLM proposed that the accuracy of L2 segmental perception limits the accuracy with which L2 sounds are produced, the SLM-r hypothesis proposes that there is a strong bidirectional connection between production and perception. In the same vein, it will be meaningful to explore what EFL learners struggle with in discriminating certain pairs of English, as it can be linked to their production of English.
When target language phonemes are new when compared to their native language, L2 learners might find it hard to acquire foreign phonemes. For instance, Korean EFL learners have difficulties in producing English fricatives which are not in the inventory of Korean and consequently tend to replace English fricatives with stops (Cho, 2010). Contrasts of ambiguous sounds that are not contrastive in the L2 learner’s native language are especially difficult to identify (Escudero, 2005; Flege et al., 1997; Morrison, 2003). Mueller (2019) showed that as Japanese EFL learners do not have a separate contrasting fricatives, they often perceive English /h/ and /f/ as the same sound. Moreover, Lambacher et al. (2001) showed that Japanese EFL learners find it hard to distinguish seat and sheet, as Japanese has sound similar to English /s/ and /ʃ/, but they do not form a contrast within the Japanese phonemic inventory when they precede the vowel /i:/.
Previous studies that investigate the perception of English by Korean EFL learners mainly examined adult learners (e.g., Cho, 2010; Cho & Jeong, 2011). Cho (2010) analyzed anterior coronal consonants. Cho & Jeong (2011) explored perceptions of some English stops and fricatives /ɵ, ð, s, z, t, d/. Johnson (2011) analyzed only voiceless English fricatives by Japanese EFL learners. The purpose of this study is to examine the confusion among voiced and voiceless English fricatives using perceptual data from young EFL learners. Despite the fact that young learners are thought to acquire a foreign language with less effort than adults (Snow, 2014), they were chosen to see if they encounter difficulties discriminating new consonants. This is because young learners benefit most from segmental feature teachings (Choe et al., 2020), and it necessitates a more urgent exploration of their perceptions.
Brown (1988) and Catford (1987) proposed a ranking of segmental differences in terms of Functional Load Principle in English pronunciation. The functional loads of segments (vowels and consonants) are investigated and listed segmental contrasts that are ranked based on their communicative value. These contrasts were developed from minimal pairs in frequently used words, the degree of neutralization among regional English dialects, and the segmental position within a word (Suzukida & Saito, 2021). The consonants are differentiated by their syllable locations, which are beginning and final. According to related research, segmental characteristics can have a significant impact on understanding (Fayer & Krasinski, 1987), but not all segmental mistakes are equally weighted (Kang & Moran, 2014). According to the Functional Load Hypothesis, some segmental mistakes are worse than others; that is, they are more likely to impede listeners’ understanding. Intelligibility would not be reduced if L2 speakers pronounce they as dey. The replacement of /b/, on the other hand, has a higher functional load, and saying bit instead of pit is likely to influence intelligibility. The functional loads of segments (vowels and consonants) are investigated, and segmental contrasts are identified and rated according to their communicative significance.
Kang & Moran (2014) categorized 120 nonnative speakers’ speech segments with their error types according to the positions in syllables (word initial, medial, and final) and classified them as high function load versus low functional load, following Catford (1987). The segments ranked 0% to 50% are coded as low functional load, whereas the segments ranked 50% to 100% are coded as high functional load (Kang & Moran, 2014). The results from Kang & Moran (2014) discovered that when comparing proficiency level groups, high low functional load segmental speech errors dropped dramatically among high proficiency level learners, compared to low functional load errors. It demonstrated that among segmental and syllable errors in speech productions, significant differences were observed mainly in the high low functional load errors between different proficiency groups. How Korean EFL learners at their beginning stage in English perceive the phonemes and the comparison with the functional load hierarchy are still yet to be known. The present study aims to examine Korean elementary EFL learners’ phonemic awareness and compare if they reflect the functional load hierarchy.
3. Methodology
The study recruited 121 Korean elementary EFL learners from a single school in Gyeonggi Province, where English is learned in the EFL context. Participants were in grades 3rd to 4th and ranged in age from 8 to 10 years old (mean age=9 years). Some outliers were excluded, such as students with developmental disabilities or those who had previously attended an English-speaking international school or kindergarten for more than one year. The participants’ native language is Korean, and they reported no hearing or language issues. Two experiments were taken in different days and participants were the same except that two students1 were absent on the Experiment 1. Table 1 describes the participants’ distribution.
| Grade 3 | Grade 4 | Total | |
|---|---|---|---|
| Male | 24 | 29 | 53 |
| Female | 36 | 32 | 68 |
| Total | 60 | 61 | 121 |
Table 2 illustrates a distribution of the participants’ English listening proficiency (Section 3.2.1. provides a detailed description of the testing instruments). Fourth-graders have higher average listening scores compared to third-graders, who start their English education in public schools. Although the standard deviation is higher for third-graders, both grades show somewhat similar score distribution patterns, with standard deviations ranging from 20 to 25.
| N | min | Max | Mean | SD | σ2 | |
|---|---|---|---|---|---|---|
| Grade 3 | 60 | 75 | 170 | 142.87 | 24.76 | 612.93 |
| Grade 4 | 61 | 86 | 170 | 151.87 | 21.86 | 477.68 |
| Total | 121 | 75 | 170 | 147.41 | 23.68 | 560.63 |
Test of Practical English Language (TOPEL) was used to group children’ English listening proficiency levels. This examination was developed by the Korea Competency Development Evaluation Institute, a non-profit organization operating under the Seoul Metropolitan Office of Education in South Korea. The full test assesses the four key language skills: listening, speaking, reading, and writing. This research specifically inspects the listening component only of the Junior Level 3 examination. The listening assessment segment of the examination is designed to systematically and progressively evaluate candidates’ proficiency in understanding spoken English. This assessment spans approximately 30 minutes and comprises a total of 33 items, with a maximum attainable score of 132 points. These items encompass a diverse range of question types2 to gauge various aspects of listening comprehension. During the time this research was conducted, students took the examination as part of their end-of-semester diagnostic assessment in their regular English curriculum. The researcher accessed the examination data to differentiate students’ proficiency levels within the listening domain.
The tests were consisted of phoneme identification of voiceless fricatives (Experiment I) and voiced fricatives (Experiment II). Each task lasted 25 minutes overall. They were administered on a separate day considering the concentration span of the young participants.
The stimuli are composed of a total of 40 nonsense syllables3 in a consonant-vowel (CV) type. They are consisted of two categories: voiceless and voiced fricatives. In the first experiment, the syllables are five voiceless fricatives (/f, s, ∫, θ, h/) with a varied-vowel environment (/i, ε, a, o, u/) by different native speakers of English. In the second experiment, syllables are made up of three voiced fricatives (/v, ð, z/) with the same vowel environment. Given the age of the participants, the phonetic symbols might be challenging and uninteresting. As a result, the symbols are presented in the form of friendly cartoon characters, Alphablocks (2013) as shown in Figure 1. The speech samples are obtained by recording them from a publicly accessible website that offers HVPT stimuli, English Accent Coach4 (Thomson, 2018a). It features nearly all English sounds, allowing individual students to easily assess their phonemic awareness and get customized training tasks. The stimuli are collected from level 1 (initial consonant with /a/), 2b (initial consonant with /i, u/), 3a (initial consonant with /o/), and 3b (initial consonant with /ε/) from the website. The stimuli are repeated three times, making a total of 120 tokens (3 times×40 stimuli). Only minimal pairs that consonants differ in the beginning position of the syllables are selected considering the perception levels of young learners.

Figure 2 depicts the online worksheet screen for the phoneme identification test in which participants are participating. They have previously learned phonemic symbols as Alphablocks cartoon characters (Figure 1) in their regular English school lessons. For the answer choices, the characters are provided next to the phonemic symbols, along with words that include the phonemes, making it easy for young learners to identify the phonemes. If participants found it difficult to determine the sound, they were encouraged to choose the other option with a photo of a baby expressing curiosity rather than selecting any random answer. After listening to the auditory cues and clicking on the answer, participants proceed to the screen where they can provide answers to the next question by clicking the next button. The screen layout remains the same for all other questions. During the experiment, some participants were observed quietly articulating the phonemes after listening to the auditory cues.

A researcher who is also a teacher obtained approval from the Institutional Review Board (SNU IRB No. 2301/002-002) for recruitment. The researcher explained the process of the experiment to the students and also promoted it to the parents in order to recruit students who wished to participate in the experiment. Then, the researcher obtained consent from the students’ guardians for those who wished to participate in the experiment. The participation period lasted for two days, with a maximum of 30 minutes each, scheduled immediately after regular classes. The phoneme identification test was conducted in a quiet room while sitting at a sufficient distance. The room was located in the school that had audio facilities and internet access available. Participants listened to audio and submitted their responses to an online questionnaire using school-owned tablets. As compensation for participating in the experiment, detailed individual diagnostic reports and a small token snack were provided.
First, participants were given instructions on each phonetic character and how they sound in order for them to recognize each character. The participants had already been introduced to each phoneme through characters and animations in their regular English class. As a result, they might find it less challenging to identify phonemes through familiar cartoon characters. Then, they were asked to select the correct phonetic character on online worksheets after listening to the audio cues. The count is made with all the correct answers and errors that participants make.
The identification test answers are summarized in confusion matrices in Tables 3 and 4. They are then projected into a perceptual map using multidimensional scaling analysis in Figures 3 and 4.
| f | θ | s | ʃ | h | Other | Total | |
|---|---|---|---|---|---|---|---|
| f | 336 | 119 | 35 | 48 | 21 | 36 | 595 |
| θ | 240 | 153 | 79 | 69 | 22 | 32 | 595 |
| s | 40 | 84 | 263 | 165 | 15 | 28 | 595 |
| ʃ | 18 | 35 | 122 | 387 | 13 | 20 | 595 |
| h | 28 | 56 | 9 | 85 | 396 | 21 | 595 |
| v | ð | z | Other | Total | |
|---|---|---|---|---|---|
| v | 313 | 247 | 34 | 11 | 605 |
| ð | 223 | 170 | 203 | 9 | 605 |
| z | 35 | 59 | 500 | 11 | 605 |
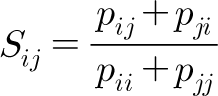

In order to conduct tests in a HVPT environment, participants were presented with combinations of five vowels and five voiceless fricatives, as well as three voiced fricatives, in randomized sequences over three sessions.
Firstly, each column in the matrix corresponds to one of the listener responses, and each row corresponds to one of the test syllables both in Tables 3 and 4. Correct responses are categorized as hits, whereas inaccuracies are labeled as false-alarms, and responses marked as ‘I don’t know’ were classified as the other. The first row of the confusion matrix shows that /f/ has been demonstrated 595 times, properly identified as /f/ 336 times and erroneously as /θ/ 119 times.
Secondly, a submatrix of response proportions for phoneme contrasts was assembled. This matrix indicates the ratio of correctly identified phonemes within the total responses for each individual phoneme.
Thirdly, similarity of confusions was computed using Shepard (1972)’s method. The formula for this calculation is as follows (Figure 3).
Lastly, a confusion map was visualized using a 9-point scale. These analyses were performed separately for both voiceless fricatives and voiced fricatives in two distinct experimental contexts. The confusion maps were generated for visualization purposes by using an Excel sheet from the publicly accessible website, Perceptual Maps5 (Fripp, 2023), which provides Multidimensional Scaling Analysis.
The phoneme identification test results are then compared to the functional load theory. Catford (1987) categorized relative function load of segments ranging from 50% to 100%. Referring to Kang & Moran (2014)’s classification codes of relative functional loads, phoneme pairs with percentages of 50 or higher are classified as high functional load and those with percentages below 50 are marked as low functional load.
Not every phonemic pair could be classified. Prior research did not list functional load for all phonemic pairings. This study, in particular, conducted separate investigations based on the presence of vocal fold vibration (i.e., voiceless or voiced) and in initial consonants, resulting in classifications of only nine pairs.
4. Result and Discussion
The Figures 4 and 6 below show results to answer the first research question (To what extent do Korean elementary EFL learners perceive English fricatives as distinct? How are their responses shown in perceptual space?). The figures are visualizations of confusion matrix of the phonemes with their relative distance in the perception. The ones that are far apart are not really competing, as they are perceived to be quite different. The closer the phoneme is to the other one, the stronger the association with it.

The perceptual confusion map of voiceless fricatives (Figure 3) provides insights into the degree of challenge or uncertainty students face when trying to discern voiceless fricative phonemes. A hierarchical cluster analysis found two levels of commonality among the sounds. In the perceptual map, /f/ and /θ/ cluster together at the first level of clustering, while /h/ and /ʃ/ cluster together. Meanwhile, /s/ exists at a distance.
In the realm of voiceless fricatives, similar outcomes to previous research were observed, yet one notably distinct pattern emerged. Using Miller & Nicely (1955)’s confusion data by L1 English adult learners, Johnson (2011) showed clustering patterns with a perceptual confusions map (Figure 6).
Commonalities include the clustering of the voiceless labiodental fricative /f/ with the voiceless postalveolar fricative /θ/, and the proximity of the voiceless glottal fricative /h/ to the voiceless postalveolar fricative /ʃ/. However, a difference arises in the positioning of the voiceless alveolar fricative /s/. While in Miller & Nicely (1955) targeting L1 learners, /s/ clustered closely with /f/ and /θ/, in present study targeting EFL learners, /s/ is positioned somewhat distantly. This discrepancy could be attributed to the influence of the participants’ native language system. That is, for Korean learners, /θ/ may be perceived differently from /s/, because /θ/ is a new and unfamiliar sound that doesn’t exist in Korean.
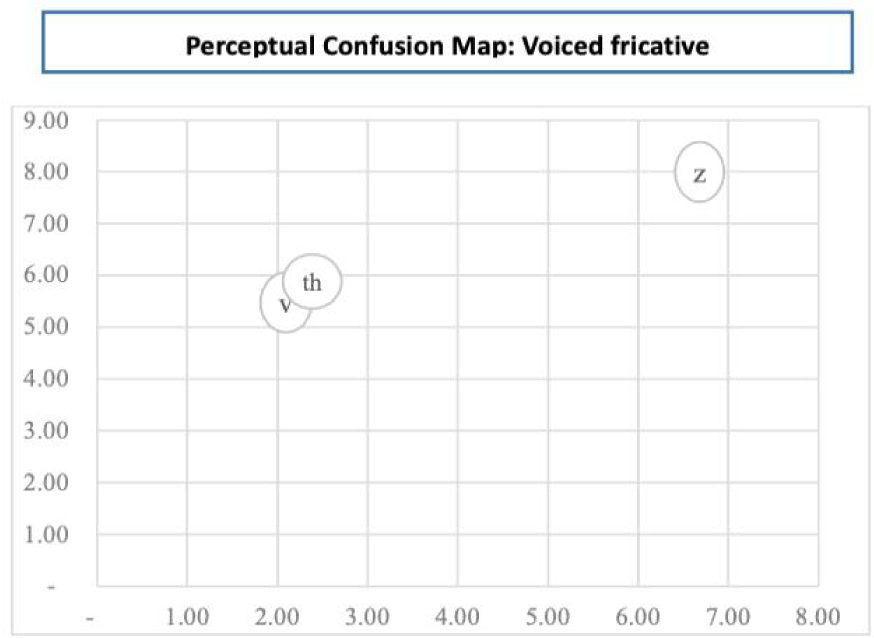
Figure 4 shows the perceptual confusion map of voiced fricatives of the participants. Clustering of /v/ and /ð/ for voiced fricatives is tightly linked with a perceptual dimension, leaving /z/ behind. It implies that if the alternation between /ð/ and /z/ is evident in the learners’ speech, it may not be solely driven by auditory or perceptual similarity; there will likely be other variables at play (Johnson, 2011).
An intriguing aspect is the resemblance between the findings for voiced fricatives in Experiment 2 and Miller & Nicely (1955). Both studies reveal proximity between the voiced labiodental fricative /v/ and the voiced interdental fricative /ð/, while the voiced alveolar fricative /z/, a sibilant sound, remains relatively distant.
Comparison of Figures 3 and 4 with Table 5 answers the second research question (Does the phonemic awareness of Korean EFL learners differ according to the functional load hierarchy? If so, to what extent do their responses differ?). When examining the classification of high or low functional load phonemes and their positions in the perceptual confusion map, the results are quite intriguing. Firstly, regarding voiceless fricatives, young Korean EFL learners effectively distinguished most of the high functional load sound pairs (e.g., f/s, f/h, s/ʃ, and s/h). These four sound pairs are located in significantly distant positions on the perceptual confusion map, indicating the learners’ successful differentiation of high functional load sounds. This suggests that due to the characteristics of young learners, acquisition and learning occur concurrently. Secondly, for one pair, ʃ/h, it was observed to be in very close proximity on the confusion map, indicating that learners had difficulty distinguishing between these two sounds. Considering that mispronunciations of these sounds can greatly affect speech clarity and how learners’ proficiency is perceived (Kang & Moran, 2014), it underscores the crucial need to cultivate phonemic awareness among Korean EFL learners, especially concerning the challenging ʃ/h consonant pair. Thirdly, despite being categorized as low functional load, the f/θ pair highlighted learners’ struggles in distinguishing them due to their proximity on the perceptual map. This suggests challenges in discerning the sounds /f/ and /θ/.
| Phoneme pairs | Number | |
|---|---|---|
| High | f/s, f/h, s/ʃ, s/h, ʃ/h | 5 |
| Low | f/θ, s/θ, v/ð, v/z, ð/z | 5 |
Finally, regarding voiced fricatives, all pairs (v/ð, v/z, and ð/z) could be labeled as either high or low functional load. An interesting observation is that all three voiced fricative pairs were classified as low functional load. Notably, on the perceptual confusion map, the v/ð pair is positioned closely, indicating that the participants had difficulty distinguishing this pair. Hence, it indicates the need for specific guidance on the classification of these phonemes. Analyzing the results of experiments allowed for the exploration of the roles of phonemes in language instruction, categorizing them based on their functional significance to identify key aspects within the teaching method.
5. Conclusion
The findings of this study contribute to a deeper comprehension of the linguistic aspects involved in Korean elementary EFL learners’ auditory processing for speech perception. An essential aspect lies in the construction of a perceptual confusion inventory of English phonemes among Korean EFL learners, a hitherto unexplored area. Additionally, this study sheds lights on the developmental progress of young learners in the early stages of their learning journey.
This study has some educational implications. To begin, it shows that the phoneme identification test can be used as a diagnostic tool to better understand learners’ phonemic awareness. It might highlight how learners use their auditory cues in the perception of phonemes. It will serve as a resource for determining what and why Korean EFL learners have difficulty perceiving or producing English fricatives. Secondly, the comprehensive examination of young EFL learners’ phonemic awareness is approached within the framework of the functional load theory (Brown, 1988; Catford, 1987). On the educational standpoint, the findings will help in determining which phonemes will be included as instructional goals or in teaching materials. Furthermore, it will aid in prioritizing what to teach first for segmental characteristics in L2 teaching. To sum, the findings of the current study could serve as valuable pedagogical insights in the language curriculum and instruction development. Finally, it calls for the future research comparing elementary school students who are fairly capable of both learning and acquisition of a second language, with adults who may rely more on learning itself. Further research would provide valuable insights into the distinct language acquisition and learning processes in age groups.
Although current studies provide some important implications, there are some limitations. Firstly, as Derwing & Munro (2015) point out, even learners of the same L1 background might differ in terms of what L2 sounds they find difficult. Hence, a solution to further address learner differences is needed. Diagnosing individual learners with their confusions across multiple categories to determine where they need improvement can be the solution. Secondly, only young learners who had just begun learning English took part in this study. Although they can give implications in the beginning stages of the learning process, older learners with more years of studying English might help understand the process in a different way. Thirdly, because this study is focusing on young learners, only the initial positions of the syllables are examined. Phonemic awareness in the other positions in syllables (e.g., word medial or word final) would provide insights into a different view. Future research could also delve into the impact of various vowel combinations with differing degrees of distinctiveness. Finally, distinct experimental conditions were established based on voicing in the current study, considering participants’ age and cognitive load. However, conducting research that integrates these conditions in one experiment could potentially yield further insights and provide a more comprehensive understanding of the phonemic awareness of EFL learners. Additional research is needed to broaden this study beyond fricatives and include a wider spectrum of phonemes.