





1. Introduction
This study investigates the perceptual motivation of dissimilation by means of a perception experiment with Korean oral stops of three distinctive laryngeal features. Dissimilation is a phonological process in which a segment becomes less similar to a nearby segment concerning a specific feature (Bye, 2011). It was initially observed in diachronic studies of language. For instance, the Latin word arbor for ‘tree’ evolved into arbol in Spanish, and the Classical Greek word hepta for ‘seven’ became efta in Modern Greek (Cser, 2013). Subsequently, typological studies demonstrated dissimilation as a synchronic phonological process in various languages (Bye, 2011; Suzuki, 1988; Walter, 2007). It was also found that dissimilation is present in the lexicon as a phonotactic constraint (Davis, 1991; Gallagher, 2010; MacEachern, 1999; McCarthy, 1986; Yip, 1989). Recently, probabilistic dissimilatory patterns in the lexicon were discovered to influence morphophonological processes in Korean (Ito, 2014; Kang & Oh, 2019; Kim S., 2016).
Dissimilation shares similarities with assimilation, although it is conceptually the opposite. Firstly, the trigger and the target can be either adjacent or distant from each other. Secondly, the direction of the effect can be progressive or regressive. Thirdly, the features involved in both processes encompass various phonological features such as place, manner, and laryngeal ones.
Despite having many similarities, dissimilation does not occur as frequently as assimilation does. Diachronically and synchronically, assimilation is by far more productive and extensive than dissimilation. What is the cause of such asymmetry between these two phonological processes? The answer to this question could be explored in the origins of the processes. According to Kiparsky (2003), sound change originates through synchronic variation in the production, perception, and acquisition of language. While the variation in speech production is gradient, arising from natural articulatory processes, the variation stemming from perception and acquisition drives alternating parsing, which can proceed in abrupt discrete steps.
Assimilation is known to be rooted in articulatory variation, even when it occurs between non-adjacent segments. For instance, vowel harmony, a type of assimilation, has been argued to result from vowel-to-vowel coarticulation (Beddor et al., 2002; Cho, 2004; Gay, 1974, 1977; Manuel, 1990; Manuel & Krakow, 1984; Öhman, 1966, among others). Similarly, consonantal harmony is claimed to be motivated by the temporal extension of articulatory gestures (Gafos & Lombardi, 1999; Walker et al., 2008; Whalen et al., 2011).
While assimilation is primarily attributed to articulatory variability, which is gradient, dissimilation is not considered a natural articulatory process. It is thought to arise abruptly through perceptual reanalysis (Kiparsky, 2003). In historical phonology, dissimilation is classified as a psychological change, alongside analogy, haplology, and metathesis (Scheer, 2015). These abrupt changes largely affect individual words, explaining why dissimilation typically manifests as a tendency in the lexicon rather than as rules in phonology (Murray, 2013). Blevins (2013) also asserts that the origin of dissimilation lies in the intrinsic phonological ambiguity of the phonetic signal, leading to divergent percepts.
According to the co-articulation hypercorrection theory (Ohala, 1981, 1993, 1997, 2012), dissimilation occurs when the listener reverses a perceived co-articulation. Therefore, dissimilation is expected to occur only with features having acoustic cues significantly extended in time.1 Alternatively, dissimilation may arise from challenging processing conditions (Frisch et al., 2004). In this perspective, the repetition of similar sounds is avoided due to the difficulties associated with processing the sequencing of similar segments.
Indeed, Coetzee (2005) provides evidence for the psychological reality of dissimilation.2 He observes the absence of /spVp/ and /skVk/ sequences in the English lexicon (while /stVt/ is present). To investigate this phenomenon, three sets of continua were developed for a perception experiment: [k]–[p], [k]–[t], and [p]–[t]. Each continuum consisted of eight tokens, which were incorporated into six words, as illustrated in Table 1.
As hypothesized, the continua were generally perceived to differ from the preceding consonant. [p]–[k] stimuli were more likely to be recognized as [p] in [skɑ_] than in [spɑ_]. This finding could be attributed to the influence of phonological grammar learned based on the lexicon. But even though [stʌt] or [stɛt] is allowed in English, listeners tended to judge the [p]–[t] and [k]–[t] stimuli not as [t] when it is preceded by another [t]. Consequently, the results reinforce the psychological reality of dissimilation with a perceptual bias against repeated consonants.
While voice onset time (VOT) dissimilation could be identified in articulatory variation3, recent findings indicate it is not always the case that there is a phonetic precursor of dissimilation in the articulatory variation of repeated aspirated stops in Korean. Oh et al. (2020) reported that long VOTs of C1 are shortened when nonadjacent C2 has also long VOTs in Korean. For instance, C1 VOT of aspirated stops was significantly shorter before another aspirated stop. However, they found that the VOT shortening effect is bidirectional in that not only C2 long VOT shortened C1 VOT, but also C1 long VOT shortened C2 VOT. In their successive study, it was replicated that both aspirated stops are realized with shortened VOT, not just one (Kang & Oh, 2024). These studies lead us to a perception study in search for the motivation of dissimilation.
Building on the previous arguments regarding the origin of dissimilation, we investigate the clues of VOT dissimilation in the perception of repeated aspirated stops in Korean. Similar to Coetzee's (2005) examination of the perceptual motivation of place-OCP in English, this study aims to illustrate how laryngeal dissimilation is driven, using aspirated stops in Korean. Additionally, while Coetzee's study explored the effect of the preceding consonant, we will focus on the impact of the following one. By demonstrating that the perception of an aspirated stop is affected by another aspirated stop in the following syllable, we will claim that VOT dissimilation in Korean is perceptually motivated.
2. Methods
The stimuli were obtained from data collected in Kang & Oh's (submitted) study, where 16 Korean speakers produced 46 different types of C1aC2a nonce words.4 C1 and C2 were chosen from nine Korean oral stops (p, ph, p’; t, th, t’; k, kh, k’) or /n/. The data from one female and one male speaker were selected, and 10 tokens were then extracted from each speaker, as detailed in Table 2. For C1, one aspirated stop and one lenis stop for each of the three places of articulation were utilized (six in total), and for C2, alveolar aspirated, lenis, tense, and nasal stops (four in total) were employed.
C1 was extracted with 40 ms of the following vowel, and C2 was extracted with 50 ms of the preceding vowel and so the total length of V1 was 90 ms. V2 was also 90 ms, taken out with C2. The durations of VOT and closure were determined in consultation with the mean values of the entire dataset in Kang & Oh (submitted, see the table in footnote 11). The VOT of C1 was manipulated into seven steps with 10 ms intervals, ranging from 70 ms to 10 ms.5 These steps were then concatenated with four different C2s, resulting in a total of 168 tokens (6 C1×7 steps×4 C2) for each speaker.
A total of 32 Korean speakers (24 females and 8 males) who were college students at a university in Gwangju participated in the perception experiment. They were all born and raised in Gwangju and South Jeolla Province and no one reported a problem with hearing. They were all paid for participation. They were evenly divided into two groups, with 12 female and 4 male speakers in each group. One group listened to stimuli from the male speaker, while the other group listened to stimuli from the female speaker. The experiment consisted of two main blocks in which the tokens were given in random order. Before the main blocks, the participants went through a practice session involving non-manipulated tokens. It was structured as a forced-choice task, where participants were instructed to choose one of the three laryngeal types for C1 (e.g., ph, p, p’) after listening to each nonce word.6 On average, the experiment lasted about 15 minutes.
For each token (168 tokens×32 participants=5,376 tokens), response and response time (RT) were recorded. A total of 41 tokens marked as 'no response' were discarded7, resulting in 5,335 valid responses and RTs for statistical analyses.
3. Results
C1 type clearly determines the response results, as illustrated in Table 3. When the base of C1 was lenis, it was identified as lenis 99% of the time, irrespective of VOT duration. Additionally, RT was significantly shorter when the base of C1 was lenis (p<.001), indicating that the choice was easier for the participants. Consequently, the subsequent statistical analyses were conducted solely with the data where the base of C1 was aspirated. From this dataset, the 30 responses indicating lenis were excluded for logistic regression analyses since the responses were not affected by VOT steps nor by C2. Aspirated and tense responses were coded as 0 and 1, respectively.
| C1type | Response | Total | ||
|---|---|---|---|---|
| Aspirated (%) | Lenis (%) | Tense (%) | ||
| Aspirated | 2,273 (85.6) | 30 (1.1) | 352 (13.3) | 2,655 |
| Lenis | 13 (0.5) | 2,653 (99.0) | 14 (0.5) | 2,680 |
The data underwent logistic regression analyses using the mixed-effects model in R (R Core Team, 2021). The independent variables considered were C1 type (aspirated and lenis), C1 place (coronal, dorsal, and labial), C1 VOT (ranging from 10 to 70 in seven steps), Voice (female and male), and C2 type (aspirated, lenis, nasal, and tense).8 Participant was treated as a random effect. The gender of participants did not have a significant impact on the results and was therefore excluded from the analysis. The final results are presented in Table 4.9
As anticipated, C1 was more likely perceived as tense as the VOT of C1 became shorter. However, even when VOT was at its shortest (10 ms), tense responses remained below 50%. In contrast, when VOT was 50 ms or longer, the majority of tokens were perceived as aspirated (refer to Figure 1).
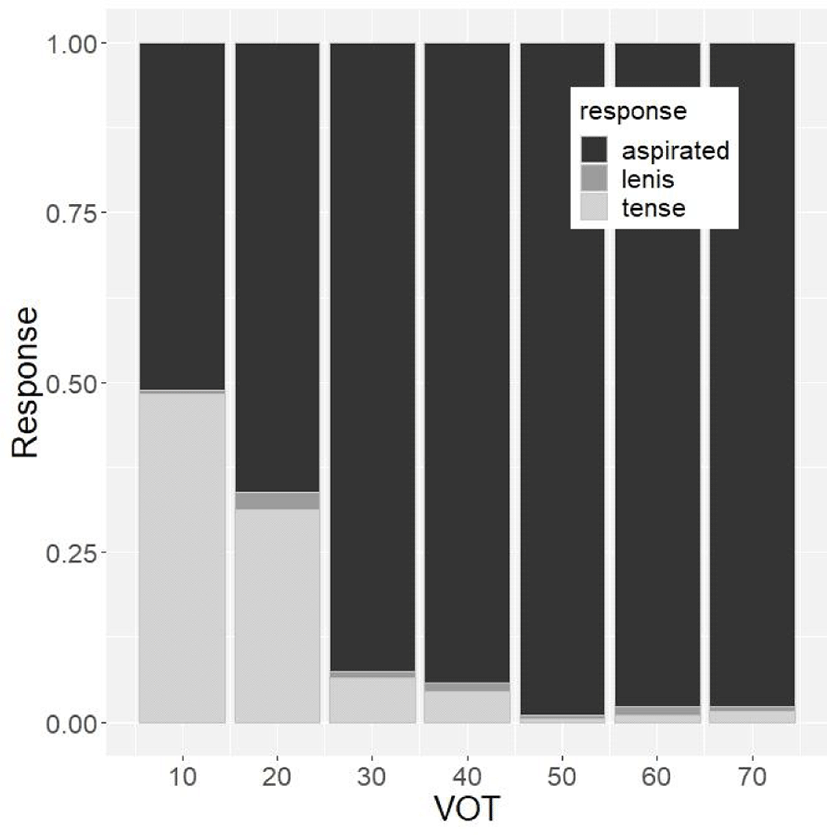
The judgment was also influenced by C2. The effect of C2 on tense responses is shown in Figure 2. Generally, a tense response was more probable when C2 was aspirated compared to when it was nasal. However, there was no significant difference in tense responses between aspirated C2 and lenis C2 conditions.
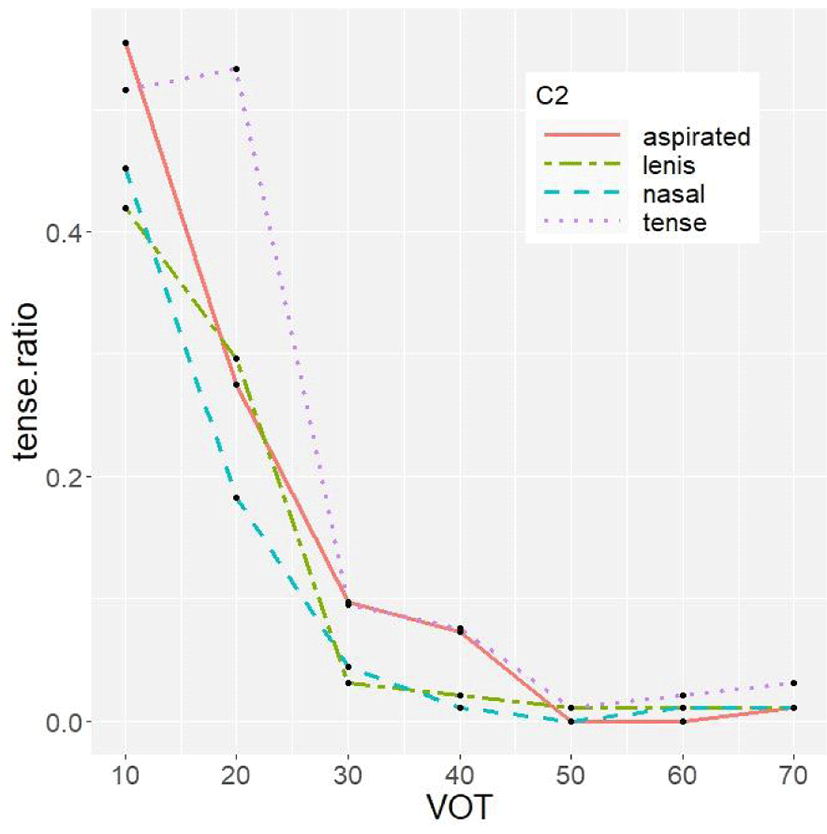
The ratio of tense responses was higher at 10 ms, 30 ms, and 40 ms VOT when C2 was aspirated or tense compared to when it was lenis or nasal. At 20 ms, the ratio was predominantly higher when C2 was tense. Interestingly enough, a tense C2 significantly elevated the ratio of tense response compared to an aspirated C2. To be specific, when C1 VOT is 20 ms, the ratio of tense response is very high when nonlocally followed by a tense C2 but it is drastically dropped when nonlocally followed by an aspirated C2.
The effect of C1 place on tense responses was also found as shown in Figure 3. The ratio was significantly lower when C1 was labial compared to other places of articulation. The difference between coronal and dorsal C1 with respect to the ratio of tense responses was not significantly different.

Next, we will examine the analysis of RT. RT was subjected to regression analyses with the same factors. Table 5 demonstrates the results of regression analysis regarding RT.
Figure 4 shows the results of RT as a function of C2 type. The shorter the VOT, the longer it took to make a judgment. Tense C2 required a significantly longer time for the choice. Coronal C1 significantly shortened RT. The male voice required more time to make a judgment than the female voice.

To summarize the results from the perception experiment, lenis-based C1 was mostly perceived as lenis but aspirated-based C1 was judged as aspirated or tense. Short VOT raised the ratio of tense response, which was also elevated by tense C2, followed by aspirated/lenis C2 and nasal. For these effects, RT was long proportionally to the ratio of tense response. This suggests that when a participant made a decision toward tense, the token was perceptually ambiguous, in general.
4. Discussion and Conclusion
This study aimed to investigate the phonetic motivation behind VOT dissimilation in Korean, specifically examining whether and how an aspirated stop influences the perception of another aspirated stop in the preceding syllable. The findings revealed that Korean listeners exhibit a perceptual bias against consecutive aspirated-aspirated onsets. An aspirated stop in the second syllable decreased the likelihood of perceiving another stop in the first syllable as aspirated. When combined with the results of the previous study (Coetzee, 2005), it becomes evident that dissimilation is more attributable to perception than production. While Kang & Oh (submitted) do not clearly show the origin of dissimilation in the variation patterns of production data, this study decisively demonstrates that dissimilatory patterns can emerge in the process of perception. However, it is noteworthy that C1 tokens constructed from an aspirated stop were perceived as aspirated more than 50 percent of the time, even when VOT was at its shortest (10 ms). This is ascribed to the 40 ms of vowel taken from aspirated stops with VOT, which contained other acoustic cues for aspirated stops. From this result, it is suggested that such a misperception would be least probable, if not possible, giving a hint for the unproductivity of dissimilation.
While aspirated-aspirated pairs were perceived toward dissimilatory patterns, aspirated-tense pairs leaned toward assimilatory ones in perception. Namely, aspirated C2 retarded the recognition of aspirated C1 whereas tense C2 accelerated that of tense C1. This result provides insight into why tense-tense pairs are preferred in Korean (Kang & Oh, 2016, 2019; Kim H., 2016). The preference of tense-tense pairs is supported by two facts. Firstly, tense-tense pairs are overrepresented in the Korean lexicon. Secondly, word-initial lenis stop more likely undergoes tensification when followed by a tense stop in the following syllable. This preference seems to be, partially, based on the perceptual bias found in the current study. The asymmetry of aspirated and tense C2 effects is also found in the transitional patterns of responses. The ratio of tense response gradually decreased in the aspirated C2 condition, but it sharply dropped between 20 ms and 30 ms in the tense C2 condition (refer to Figure 2). In addition, a tense C2 significantly delayed the judgment (refer to Figure 4). Taking these differences into account, we speculate that tense C2 affects the perception of C1 in a different way from aspirated C2. When the listeners are exposed to tense C2, the judgment can be influenced not only during the online processing of speech sounds, but when retrieving the first consonant from their short-term memory. This hypothesis will be explored in future study.
This study affirmed the critical role of F0 in distinguishing lenis stops from others, consistent with previous research (Ahn, 2000; Kang 2014; Kang & Guion, 2008; Kim & Duanmu, 2004; Lee & Jongman, 2012; Lee et al., 2020; Silva, 2006a, 2006b, among others). When listening to tokens constructed from lenis stops, 99% of responses were lenis, regardless of the VOT duration. Conversely, with tokens from aspirated stops, 98.9% of responses were either aspirated or tense. It is inferred that the 40 ms vowel portion taken from the base provided sufficient acoustic information, particularly in terms of F0, for the distinction. In addition, lenis stops in Korean are permitted to have a broad range of VOT depending on their positions. They are manifested by long VOT in word-initial position but by short VOT in intervocalic position due to intersonorant voicing. Thus, Korean speakers tend to have a more lenient attitude toward the VOT values of lenis stops. The results clearly demonstrate that the low F0 of the vowel onset is firmly associated with perceiving lenis stops in Korean.
Finally, the effect of place on stop category perception can be attributed to phonetic differences among stops. VOT in aspirated stops is in general long in the order of dorsal > coronal > labial (Kim, 2019, 2021; Lee & Yoon, 2016; Silva, 2006a, etc.).10 Thus, when the VOT values are 30 ms to 40 ms in Figure 3, dorsal C1 was more perceived as tense compared to labial or coronal C1s since VOT values of dorsal stops need to be long enough to be perceived as aspirated.11 In contrast, labial stops were least likely to be perceived as tense, presumably because labial aspirated stops are characterized by relatively short VOT. Considering that the duration of VOT is not significantly different between labial and coronal stops in many studies, we need to investigate whether identical place of articulation between C1 and C2 can affect the C1 stop category perception. Since the C2s in this study were all coronal, the ratio of tense responses might have increased in the coronal C1 condition because of identity effect. As aspirated C2 hindered the recognition of aspirated C1, which is identical to C2, the identity of place could have been another reason for the difference between coronal and labial. This aspect should be tested in the future, along with the effect of short-term memory (Goldinger et al., 1999).