





1. 서론
가수는 본인의 신체적 조건과 발성 능력에 부합되는 성종(voice classification)을 파악하여 그에 맞는 음악으로 훈련하고 가창하여야 한다. 성종은 일반적으로 후두 크기, 성대 길이 및 공명강 길이 등의 신체적 조건과 음성사용 방법, 개인의 산출 가능한 음역에 따라 세분화한다(Lee, 2008). 남성의 성종은 테너(tenor), 바리톤(baritone), 베이스(bass)로 구분하고, 여성은 소프라노(soprano), 메조소프라노(mezzo soprano), 알토(alto)로 구분한다. 특히 성악가는 성종을 구분하는 것이 매우 중요하며, 각 성종에 맞는 노래로 훈련하고 가창함으로써 전문성악가로 발전할 수 있다. 만일 자신의 신체적 조건과 발성 능력과는 다른 성종을 선호할 경우 무리한 발성으로 인해 음성장애가 발생할 수 있으며, 성악가로서의 역할을 하기 어려울 수 있다(Nam et al., 2007).
반면, 대중가요 가수는 자신의 성종에 상관없이 주어진 곡에 맞추어 노래하거나 본인이 산출 가능한 음역보다 높은 음역의 노래를 훈련하는 경우가 많다. 대중가요는 말 그대로 대중이 즐기는 음악이기 때문에 대중이 좋아하는 곡을 잘 전달하고 표현하는 것에 초점이 맞추어져 있어 대중의 선호도가 높은 고음역의 노래가 많다(Yoo, 2016). 이에 대중가요 가수는 자신이 산출할 수 있는 음역을 정확하게 파악하지 않은 상태에서 고음역의 노래를 연습하고 부르는 경우가 흔하다(Wu & Chong, 2023). 이러한 대중가요 가수들의 음성 오·남용은 음성 문제를 초래할 가능성이 매우 높다. 특히 남성 가수가 부르는 대부분의 노래는 후렴(코러스, chorus) 부분이 C4–C5의 음역에서 이루어진다. 이 음역은 남성에게 고음역에 해당하는 것으로, 이 음역을 가창할 때 혀와 후두의 상승으로 인한 후두 주변근의 긴장이 초래되어 음성산출에 어려움이 발생할 수 있고, 성구가 전환될 때마다 음도일탈 현상이 발생할 수 있다(Titze et al., 2017).
성구(vocal register)는 연속적인 기본주파수 범위 내에서 음질이 유사하다고 지각되는 음성의 영역이다(Titze et al., 1988). 성악인은 음도가 상승하면서 성구전환이 발생할 때 호흡훈련과 발성 훈련을 통해 ‘messa di voce’기법을 사용하여 성구전환을 유연하게 함으로써 음질을 균일하게 유지시킬 수 있다(Carroll, 2000; Yoon et al., 1999). 성종별 성구전환의 차이를 설명한 Neumann et al.(2005)에 따르면, 테너는 고음역으로 갈수록 성구전환이 1–3회 정도 나타나지만 바리톤이나 베이스는 2–3회 이상을 거쳐야 고음에 도달할 수 있다. 이는 성구전환이 발생되는 음역이 바리톤이나 베이스는 테너에 비해 낮은 음역에서 발생하므로 고음역에 도달하기 위해서는 더 많은 공명 조정 과정을 거쳐야 하기 때문이다. 즉 성종에 따라 고음역을 산출하기 위해 요구되는 성구전환의 과정이 다를 수 있으므로 대중가요 가수도 본인의 성종을 정확하게 구분하여 자신의 성종에 적합한 노래를 할 필요가 있다. 특히 대중가요 가수가 되고자 하는 전공생이나 입시생의 경우 충분한 훈련이 이루어지지 않은 상태이기 때문에, 본인의 성종을 파악하지 않은 상태에서 본인에게 적합하지 않은 음역의 노래를 반복적으로 연습하게 되면 후두의 손상이 초래되기 쉽다. 이에 대중가요 가수 전공생이 본인의 성종을 파악하고 있는지를 확인하는 것은 매우 중요하다.
또한, 고음역에서는 기본주파수의 상승으로 인해 배음 주파수들이 동반 상승하게 됨으로써 노래 가사, 특히 모음을 조음할 때 배음들과 각 모음의 포먼트 간에 부조화(mismatch)가 발생한다. 이때 발생하는 소리 에너지의 손실을 줄이기 위해 포먼트 튜닝(formant tuning) 과정이 요구된다(Schutte & Miller, 1984; Titze, 2008). 훈련된 성악가는 상후두 부위(supraglottal area)의 모양과 위치를 조절하는 포먼트 튜닝 과정을 통해 모음 종류에 상관없이 고음역에서 각 모음을 자유롭게 산출할 수 있다. 다만, 이 과정에서 모음의 왜곡 현상이 발생할 수 있다. 반면, 대중가요 가수는 고음역에서의 포먼트 튜닝 과정에 의한 모음 왜곡 현상이 가사전달력을 감소시킬 수 있어 개인 역량이나 훈련 정도에 따라 고음역에서 조음의 위치가 다른 모음의 산출을 위한 포먼트 튜닝 과정이 어려울 수 있다. 특히 대중가요 가수가 되기 위해 준비 중인 경우, 각 모음에 따라 변화되는 혀와 후두의 위치를 조절하는 포먼트 튜닝 과정이 더 어려울 수 있다(Kim & Seong, 2017; Koo, 2020). 이는 대중가요 보컬 전공생이 모음 종류에 따라 산출할 수 있는 고음역의 범위가 다를 수 있다는 것을 의미한다. 가수의 성종에 따라서 산출할 수 있는 음역이 다르기 때문에 성종별로 모음 종류에 따라 정조음할 수 있는 고음역이 다를 수 있다. 고음역에서 정확하게 가사가 전달되기 위해서는 모든 모음이 해당 음역에서 정확한 음도로 정조음되어야 한다. 그러나 각 성종별로 모음 간에 산출할 수 있는 음역이 다를 경우 포먼트 튜닝 과정에 의한 모음 왜곡 현상 또는 특정 모음의 고음역 산출 불가 현상이 발생할 수 있다. 따라서 대중가요 가수를 희망하는 전공생이나 입시생의 성종을 파악하고, 성종별로 모음 종류에 따라 산출할 수 있는 고음역을 파악할 필요가 있다.
이에 본 연구는 대중가요 가수를 준비 중인 남성 전공생을 대상으로 설문조사를 통해 자신이 주관적으로 판단하고 있는 성종을 조사하고, 이를 음성평가를 통해 측정한 음역과 비교함으로써 대중가요 보컬 남성이 본인의 음역을 제대로 파악하고 있는지 살펴보고자 하였다. 또한, 각 성종에서 모음에 따라 산출 가능한 음역의 차이가 있는지, 그리고 각 모음에서 성종 간 음역의 차이가 있는지를 알아보고자 하였다. 본 연구를 통해 대중가요 보컬을 전공하거나 입시를 준비하는 남성이 본인이 산출할 수 있는 음역에 대해 좀 더 인지할 수 있도록 하고, 모음에 따라 산출할 수 있는 본인의 음역이 무엇인지를 파악하게 함으로써 무리한 고음역 산출을 위한 음성 오·남용을 예방하는 데 목적이 있다.
2. 연구방법
본 연구는 18–29세의 대중가요 보컬을 대학에서 전공하고 있거나 대학 입시를 준비 중인 남성을 대상으로 하였다. 연구대상자의 선정 기준은 첫째, 실용음악학과 또는 K-pop 학과 등의 대중가요 관련학과에 재학 중이거나 현재 관련학과의 대학 입시를 준비 중인 남성, 둘째, 청지각적 음성평가인 GRBAS 척도(Hirano, 1981)에서 G 척도가 0–0.5점인 경우, 셋째, ‘가을문단(Kim, 2012)’의 첫 번째 문장을 VOXplot(v2.0.1, 2023; Lingphon, Straubenhardt, Germany)의 Acoustic Voice Quality Index(AVQI)로 측정하여 Jitter, Shimmer, Harmonics-to-Noise Ratio(HNR), Cepstral Peak Prominence(CPPS)가 AVQI에서 제시하는 정상 범주에 속하는 경우, 넷째, 과거력상 청각장애, 호흡기질환, 신경계질환 및 후두질환의 병력이 없는 경우, 다섯째, 조음기관의 구조적 및 기능적 이상이 없는 경우, 여섯째, 자료수집일 기준 최근 2주 동안 감기 등의 호흡기질환을 경험하지 않은 사람. 일곱째, 정상 청력을 지닌 경우로 제한하였다. 본 연구에 참여한 대상자는 27명이었고, 연령의 평균(표준편차)은 20.93(18–29)세였다.
대상자가 본인의 성종이 무엇이라고 생각하는지 주관적으로 평가하도록 하였다. 성종이라는 단어가 익숙하지 않을 대중음악 전공자들을 위해 자신의 성종과 음역 두 가지로 분류하여 체크하도록 하였다. 그 결과, 본인의 성종이 테너라고 응답한 경우가 9명, 바리톤이 7명, 베이스가 3명, 모름이 8명이었다. 또한 Nam et al.(2007)와 Titze(2000)가 제시한 성종별 산출 가능한 음역(테너 C3–C5, 바리톤 G2–G4, 베이스 E2–E4) 기준을 대상자에게 제시하고 본인의 음역을 평가하도록 한 결과, 테너가 7명, 바리톤이 12명, 베이스가 4명, 모름이 4명이었다(표 1).
| Item | Voice classification | ||
|---|---|---|---|
| 본인의 성종 | 테너 | 바리톤 | 베이스 |
| 본인의 음역 | C3−C5 | A2−A4 | E2−E4 |
음성녹음은 방음시설이 갖추어진 녹음실에서 검사자의 지시에 따라 대상자가 산출한 음성을 녹음하였다. Mac Pro(2012)에 설치된 Digital Audio Workstation(DAW; Yamaha, Hamamatsu, Japan) 프로그램을 이용하여 오디오 인터페이스(Babyface Pro FS, RME Audio, Haimhausen, Germany)와 무지향성 콘덴서 마이크(Neumann TLM 103, Neumann, der Ruhr, Germany)로 음성을 녹음하고, 녹음된 음성자료의 모니터링은 모니터링 스피커(Genelec 2040d, Genelec, Stockholm, Sweden)를 통해 실시하였다. 음성녹음의 표본추출률은 44,100 Hz, 양자화는 24 bit로 하고, WAV(waveform audio format) 형식으로 저장하였다.
대상자는 의자에 바르게 앉은 상태에서 팝 필터를 장착한 마이크로부터 입술이 약 10 cm 떨어진 상태로 음성을 산출하였다. 모음 /a/를 편안한 음도와 강도로 5초간 연장 발성하도록 하였고, ‘가을문단’의 첫 번째 문장인 ‘우리나라의 가을은 참으로 아름답다’를 편안한 음도와 강도로 읽도록 하였다.
음역은 선행연구(Chung, 2000; Kim & Lee, 2019, 2021)에서 제시한 반음을 이용한 음성범위프로파일(voice range profile, VRP)을 이용하여 측정하였다. 대상자는 편안한 음도에서 시작하여 한 음에서 약 2초간 발성하고 반음씩 상승하도록 하였다. 상승 음도에서는 베이스 성종에서 성구전환(passaggio)이 주로 나타나는 A3의 음도부터 최대한 큰 소리내기와 최대한 약한 소리내기를 실시하고, 하강 음도에서는 테너의 성종에서 진성의 산출이 어려워지는 C3의 음도부터 최대한 큰 소리내기와 최대한 약한 소리내기를 실시하면서 최대 산출 가능한 고음과 저음 및 큰 소리와 작은 소리를 산출하도록 하였다(Jeong et al., 2012). 각 모음 /a/, /i/, /u/에서 동일한 방식으로 3회씩 반복 측정하였다.
연장발성 및 문장 읽기 녹음된 음성자료는 음원을 추출하여 Praat(version 6.2.03, Boersma & Weenink, 1991) 및 VOXplot의 AVQI을 사용하여 평균기본주파수(fundamental frequency, F0)와 평균발화기본주파수(speaking fundamental frequency, SFF), jitter, shimmer, HNR, CPPs를 측정하였다.
음역 평가를 위해 녹음된 음성자료는 Sygyt software(Bochum, Germany)에서 개발한 Voce Vista Pro(5.4.2.5435, https://www.vocevista.com)로 스펙트럼과 스펙트로그램을 통해 주파수와 음성강도를 측정하였다(그림 1). 음성범위프로파일 측성 시 특정 음도에서 강한 강도 또는 약한 강도로 소리를 내기 어려워하는 경우 그 음도에서는 강약을 조절하기 어렵다고 판단하여 대상자가 산출할 수 있는 음역의 한계지점으로 설정하였고(Chung, 2000; Kim & Lee, 2019, 2021), 흉성구간에서 음도를 상승시킬 때 음성강도가 급격하게 상승하는 지점과 가성으로 음질이 변화하고 음성강도가 급격하게 감소하는 지점을 각 첫 번째 성구전환과 두 번째 성구전환이라고 하였다. 이와 동일한 방식으로 각 모음에서 음역과 성구전환 지점을 측정하였다.
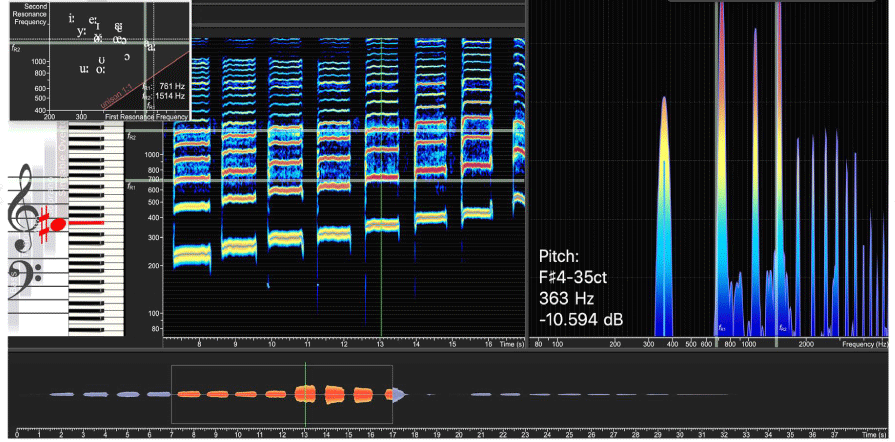
음역 측정을 위한 변수로 각 모음별로 최고기본주파수(maximum fundamental frequency, F0MAX), 최저기본주파수(minimum fundamental frequency, F0MIN), 기본주파수범위(fundamental frequency range, F0RANGE), 흉성기본주파수범위(voce di petto, F0CHEST), 가성기본주파수범위(voce di testa, F0HEAD), 첫 번째 성구전환(first register transition, 1stPASSAGGIO), 두 번째 성구전환(second register transition, 2ndPASSAGGIO)을 분석하였다. 각 변수의 정의는 표 2에 제시하였다.
각 대상자의 성종을 음향학적으로 분류하기 위하여 대상자가 산출한 음역이 Nam et al.(2007)과 Titze(2000)가 제시한 성종별 음역(표 3)과 성구전환 구간(표 4)에 부합하는지 확인하였다. 가령, 대상자의 음역이 C3–C5, 1stPASSAGGIO가 C4–E4, 2ndPASSAGGIO가 F4–A4 구간에서 측정되면 테너로 분류하였다.
| Vocal type | Voice range |
|---|---|
| Tenor | C3 (130.8 Hz)–C5 (523.3 Hz) |
| Baritone | G2 (98.0 Hz)–G4 (392.0 Hz) |
| Bass | E2 (82.4 Hz)–E4 (329.6 Hz) |
설문을 통해 수집한 대상자가 주관적으로 평가한 성종과 음향학적 평가를 통해 분석한 성종 간의 차이는 일치율로 비교하였다. 음향학적으로 평가하여 분류한 성종 간 F0, SFF 및 음역 관련 변수들을 비교하기 위해 Shapiro-Wilk의 정규성검정을 실시한 결과, 테너 성종의 F0, SFF 및 바리톤 성종의 일부 음역 관련 변수의 유의확률이 유의수준 0.05 이하로 정규성을 띄지 않아 비모수검정인 Kruskal-Wallis 검정을 사용하여 집단 간 차이를 비교하였다. 전체 대상자의 모음 간 음역 비교는 repeated measures ANOVA 사용하였고, 각 성종별 모음 간 음역의 차이는 Friedman 검정으로 분석하였다.
3. 연구결과
대상자가 본인의 성종을 파악하는지 확인하기 위해 주관적으로 평가한 성종과 음향학적으로 측정된 음역에 따라 구분한 성종 간의 일치율을 평가하였다. 그 결과, 총 27명 중 주관적 성종은 테너 9명, 바리톤 7명, 베이스 3명, 자신의 성종을 모른다는 경우가 8명인 반면, 측정된 성종은 테너 15명, 바리톤 9명, 베이스 3명이었다. 주관적 성종을 응답한 19명 중에서 주관적 성종과 측정된 성종이 일치한 경우는 11명, 일치하지 않은 경우는 8명으로 일치율은 57.8%였다.
성종이라는 용어가 대중가요 보컬 남성에게 익숙하지 않을 수 있어 성악가의 성종별 음역인 C3–C5(테너), G2–G4(바리톤), E2–E4(베이스)를 제시한 후 본인이 산출할 수 있는 음역을 응답한 것으로 성종을 분류한 결과, 총 27명 중 주관적 음역은 테너 7명, 바리톤 12명, 베이스 4명이었으며, 자신의 음역을 모르는 경우가 4명이었다. 주관적 음역을 응답한 23명 중에서 주관적 성종과 측정된 성종이 일치한 경우는 11명, 일치하지 않은 경우는 12명으로 일치율은 47.8%였다.
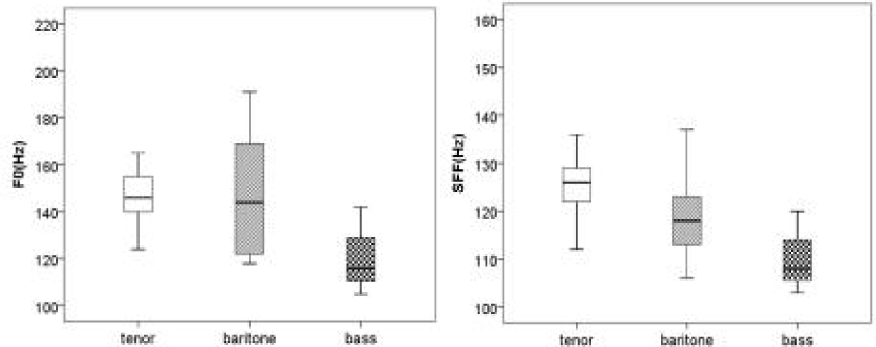
전체 대상자의 F0와 SFF의 평균(표준편차)은 각 150.33 (28.73) Hz와 122.30(10.59) Hz였다(표 5). 성종 간 F0와 SFF를 비교한 결과, F0는 성종 간에 통계적으로 유의한 차이가 없었다(χ2= 5.856, p=.054). SFF는 성종 간에 유의한 차이가 있었으며(χ2= 8.980, p=.011), 테너>바리톤>베이스 순으로 낮아졌다. 성종별 F0와 SFF의 중위수와 사분위수를 제시한 상자도표는 그림 2에 제시하였다.
| Parameter | Tenor (n=15) | Baritone (n=9) | Bass (n=3) | χ2 | p-value |
|---|---|---|---|---|---|
| F0 (Hz) | 157.60 (27.77) | 148.00 (28.56) | 121.00 (19.00) | 5.856 | .054 |
| SFF (Hz) | 127.07 (8.90) | 118.33 (9.64) | 110.33 (8.74) | 8.980 | .011* |
전체 대상자의 모음 간 음역을 비교하기 위해 각 음역 변수를 대상으로 repeated measures ANOVA를 실시한 결과, F0MAX는 Mauchly의 구형성 검정에서 구형성이 가정되지 않았다(χ2=6.363, p=.042). 이에 Greenhouse-Geisser 검정 값을 살펴본 결과, F0MAX가 모음 간에 모두 동일하지는 않았다(F=4.091, p=.031). 어떤 모음 간에 유의한 차이가 있는지 살펴보기 위해 Bonferroni를 이용한 주효과 검정을 실시하였고, 어떠한 모음 간에도 통계적으로 유의한 차이는 나타나지 않았으나 /a/>/u/>/i/의 순으로 F0MAX가 낮아졌다.
F0MIN은 Mauchly 구형성 검정 결과, 구형성이 가정되었다(χ2= 3.898, p=.142). 이에 구형성 가정 결과를 살펴본 결과, F0MIN은 모음 간에 유의한 차이가 없었다(F=.635, p=.534).
F0RANGE는 Mauchly 구형성 검정 결과, 구형성이 가정되어(χ2= 5.728, p=.057) 구형성 검정 값을 살펴본 결과, F0RANGE가 모음 간에 모두 동일하지는 않았다(F=4.279, p=.026). 이에 Bonferroni를 이용한 주효과 검정을 실시하였으며, 어떠한 모음 간에도 통계적으로 유의한 차이는 없었으나 /a/>/u/>/i/의 순으로 F0MAX가 낮아졌다.
F0CHEST는 Mauchly 구형성 검정 결과, 구형성이 가정되지 않아(χ2=12.009, p=.002) Greenhouse-Geisser 검정 값을 살펴본 결과, F0CHEST가 모음 간에 유의한 차이는 없었다(F=.306, p=.667).
F0HEAD는 Mauchly의 구형성 검정 결과, 구형성이 가정되지 않았다(χ2=6.783, p=.034). 이에 Greenhouse-Geisser 검정 값을 살펴본 결과, F0HEAD는 모음 간에 유의한 차이가 없었다(F=2.280, p=.124).
1stPASSAGGIO는 Mauchly의 구형성 검정 결과, 구형성이 가정되지 않아(χ2=7.760, p=.021) Greenhouse-Geisser 검정 값을 살펴본 결과, 1stPASSAGGIO는 모음 간에 유의한 차이가 없었다(F=2.609, p=.097).
2ndPASSAGGIO는 Mauchly의 구형성 검정 결과, 구형성이 가정되지 않아(χ2=10.422, p=.005) Greenhouse-Geisser 검정 값을 살펴본 결과, 1stPASSAGGIO가 모음 간에 유의한 차이는 없었다(F=.427, p=.655). 표 6은 모음별 음역 변수의 평균과 표준편차를 제시하였다.
각 모음의 성종 간 음역을 비교한 결과, 표 7에 제시된 바와 같이 모음 /a/는 F0MAX(χ2=11.514, p=.003), F0MIN(χ2=10.442, p=.005), F0RANGE(χ2=10.537, p=.005), F0CHEST(χ2=12.62, p=.002), F0HEAD(χ2=8.774, p=.012), 1stPASSAGGIO(χ2=15.098, p=.001), 2ndPASSAGGIO(χ2=15.156, p=.001)의 모든 변수에서 성종 간 유의한 차이가 있었다. 모음 /i/는 F0MAX(χ2=13.551, p=.001), F0RANGE(χ2= 12.338, p=.002), F0CHEST(χ2=16.834, p<.001), 1stPASSAGGIO(χ2= 19.136 p<.001), 2ndPASSAGGIO(χ2=18.252, p<.001)에서 성종 간 유의한 차이가 있었다. 모음 /u/는 F0MAX(χ2=13.271, p=.001), F0MIN(χ2= 9.563, p=.008), F0RANGE(χ2=12.215, p=.002), F0CHEST(χ2=15.134, p=.001), 1stPASSAGGIO(χ2=12.616, p=.002), 2ndPASSAGGIO(χ2=17.937, p<.001)의 모든 변수에서 성종 간 유의한 차이가 있었다. 그러나 모음 /i/의 F0MIN, 모음 /i/와 /u/의 F0HEAD는 통계적으로 유의한 차이가 없었다.
4. 논의 및 결론
본 연구는 대중가요 보컬을 대학에서 전공하고 있거나 대학 입시를 준비하는 남성 27명을 대상으로 자신의 성종과 음역을 파악하고 있는지 살펴보기 위해 주관적으로 평가한 성종과 음향학적으로 평가한 성종 간에 차이가 있는지를 비교하였고, 성종 간 F0와 SFF의 차이도 비교하였다. 또한, 성종별로 모음에 따라 고음역에서 산출할 수 있는 정도가 다를 수 있으므로 극모음 /a/, /i/, /u/간 음역 차이와 각 성종별로 모음 간 음역의 차이 및 각 모음별로 성종 간 음역의 차이를 비교하였다. 연구결과는 다음과 같다.
첫째, 대상자 본인이 주관적으로 평가한 성종과 F0, SFF 및 음역을 통해 성종 간의 일치율을 살펴본 결과. 본인이 주관적으로 판단하는 성종과 측정된 성종 간의 일치율은 57.8%였다. 성종별 음역을 제시한 후 주관적으로 판단한 성종과 측정된 성종 간의 일치율은 47.8%로 성종별 음역의 제시 유무에 상관없이 주관적으로 평가한 성종과 음향학적으로 평가한 성종 간에 일치율이 낮았다. 이는 대중가요 관련학과의 보컬을 전공하거나 입시를 준비하는 남성의 절반 이상이 본인의 성종을 정확하게 파악하지 못하고 성종의 정의와 각 성종에서 산출할 수 있는 음역에 관한 지식이 부족함을 알 수 있다. 특히 주관적으로 성종만을 응답하게 하였을 때보다 성종별 음역을 제시한 상태에서 성종을 판단하게 하였을 때 바리톤이라고 응답한 수가 7명에서 12명으로 증가하였는데, 바리톤 성종으로 제시된 음역인 G2–G4(98.0–392.0 Hz)는 대중가요의 코러스(chorus) 부분에서 많이 사용되는 음계로 대중가요 보컬이 흔히 부르게 되는 음역이기 때문에 이 음역을 자신의 성종으로 오인하였을 수도 있다.
둘째, 대중가요 전공생이나 입시를 준비하는 남성의 성종 간 F0는 유의한 차이가 없었지만 SFF는 유의한 차이를 보였으며, 테너>바리톤>베이스의 순으로 낮았다. F0는 성종 간 통계적으로 유의한 차이는 없었으나 유의확률이 .054로 유의수준에 근접한 수치였고, 테너>바리톤>베이스의 순으로 낮아졌다. 다만, Nam & Choi(2007)의 연구에 따르면, 국내 남성 성악가의 SFF가 테너는 164.8 Hz, 바리톤이 123.5 Hz, 베이스가 98.0 Hz인 반면, 본 연구에 참여한 대상자의 SFF는 테너가 127.07 Hz, 바리톤이 118.33 Hz, 베이스가 110.33 Hz로 성악가에 비해 대중음악 보컬 간의 성종 간의 F0와 SFF의 차이가 크지 않았다. 성악가는 자신의 성종을 파악하여 그에 맞는 성종의 음악으로 훈련하고, 평상시 발화에서도 본인의 성종에 해당하는 음역의 음도로 말하는 것에 익숙해져 성종 간에 F0와 SFF의 차이가 크다(Nam et al., 2010), 그러나 대중가요 보컬 가수는 본인의 성종을 정확하게 파악하지 못하고, 모든 성종이 비슷한 음역에서 노래하고 연습하기 때문에 개인의 성종에 적합한 음도에서 가창훈련을 하지 않았음을 시사한다.
셋째, 성종의 구분 없이 전체 대상자의 모음 간 음역을 비교한 결과, F0MAX와 F0RANGE에서 모음 간에 유의한 차이를 보였다. 모음 /a/의 F0MAX와 F0RANGE가 가장 높았고, 두 음역 변수 모두 모음 /u/, 모음 /i/의 순으로 낮았다. 이는 모음 /a/가 모음 /u/나 모음 /i/에 비해 더 쉽게 고음역을 산출할 수 있다는 것을 알 수 있다.
모음 유형과 상관없이 고음역으로 올라갈수록 후두의 위치는 동반 상승하여 후두의 긴장성이 높아진다(Neumann et al., 2005). 특히 모음 /i/와 /u/ 같은 고모음을 조음할 때 혀가 상승하면서 혀뿌리와 연결된 설골이 상승하게 되고, 후두의 위치 또한 동반 상승하게 된다. 고모음을 산출하면서 음도를 상승시키면 후두는 더 상승하게 되고 후두의 긴장성은 더욱 높아지게 되어 음을 산출하기 어렵거나 음도일탈 현상이 나타날 가능성이 높다. 반면, 모음 /a/는 혀의 위치가 뒤쪽 아래로 위치한 후설저모음이다. 모음 /a/의 경우 혀의 위치가 뒤쪽 아래로 형성되어 있어, 고음을 산출할 때 후두가 상승하지 않도록 조절하는 것이 다른 모음보다 용이하다. 따라서 모음 /a/가 모음 /i/나 /u/에 비해 고음역에서의 산출이 비교적 용이한 것이다. 또한 모음 /a/의 경우 구강의 면적이 넓어지며 인두강의 면적은 상대적으로 좁아지고 길어진다. 반대로 모음 /i/는 혀와 입천장이 매우 근접하여 구강면적이 매우 좁아지면서 인두강의 면적은 넓어지고 길이는 짧아지며, /u/는 인두강 바로 위의 구강 뒷부분의 구강 면적이 좁아지는 반면 인두강 면적은 상대적으로 넓어지고 길이는 짧아진다(Yang, 1998). 인두강의 길이가 짧아진다는 것은 후두가 상승하는 것을 나타낸다. 즉 모음 /a/에 비해 모음 /i/나 /u/를 산출할 때 더욱 후두가 상승하게 됨으로써 고음역을 산출하기 어려워지므로 모음 /a/가 모음 /i/나 /u/보다 F0MAX는 높고 F0RANGE가 넓어 고음역을 산출하는데 용이하다는 것을 알 수 있다.
본 연구에 참여한 대상자와의 면담과정에서 대중가요 보컬은 노래 연습 시 모음 /i/나 /u/ 보다는 모음 /a/를 주로 사용하며, 모음 /i/나 /u/를 사용하여 고음을 산출할 경우, 음도일탈이 자주 발생하고 후두의 상승으로 인한 후두주변근의 수축으로 목의 긴장이 높아져 가창 시 어려움이 초래된다고 하였다.
넷째, 대상자를 성종별로 구분하여 성종별 모음 간 음역을 비교한 결과, 모든 성종에서 모음 간에 음역 변수 모두 통계적으로 유의한 차이가 없었다. 각 성종별로 대상자의 수가 적었기 때문에 통계적인 유의성이 나타나지 않은 것으로 보인다. 다만 대상자의 수가 15명인 테너의 경우, F0RANGE의 모음 간에 차이가 통계적으로 유의하지는 않았지만 유의확률이 0.052로 유의수준 .05에 근접하였다. 테너 성종의 모음 간 F0RANGE 평균을 살펴보면, 모음 /a/는 520.87 Hz, 모음 /u/는 491.73 Hz, 모음 /i/는 472.07 Hz로 모음 /a/, /u/, /i/의 순으로 /a/>/u/>/i/의 순으로 음역의 범위가 감소함을 알 수 있다. 추후 각 성종별로 대상자의 수를 충분히 확보하여 다시 살펴볼 필요가 있다.
모음 간에 발성 가능한 음역의 차이를 해결하기 위해서는 포먼트 튜닝 과정이 필요하다. 비선형소스-필터이론으로 포먼트 튜닝 과정을 설명한 Bozeman(2013)에 의하면, 성도를 통과하는 음원을 능동적으로 변경하면 음향에너지가 생산적으로 다시 반사되어 음원의 에너지를 증가시킬 수 있다. 이러한 음원과 필터 간의 상호작용은 성대의 폐쇄지수(각 진동 주기에서 폐쇄 시간의 비율)를 높이는데 효과적이며, 성문에 큰 압박을 가하지 않고 기류를 감소시킬 수 있다. 즉 성도의 모양을 변형시킴으로써 성대의 자가 진동을 촉진하는 관성리액턴스(inertive reactance)를 증가시켜 음성산출을 용이하게 한다는 것이다. 이는 yelling(입을 크게 벌리고 인두강을 좁힌 상태) 또는 whoop(입을 작게 벌리고 인두강을 넓힌 상태) 등을 이용한 성도 모양의 변화를 통해 이루어진다. 성도 모양의 변형에 의한 포먼트 튜닝 과정은 고음역으로 갈수록 높아지는 배음주파수와 공명주파수(F1, F2)를 능동적으로 수정하여 이들을 일치시킴으로써 공명을 증가시키는 방법이다. 즉 고음역에서 모음별로 성구전환을 유연하게 하고 산출할 수 있는 음역 범위를 넓히기 위해서는 구강을 포함한 성도의 모양을 조정하는 포먼트 튜닝 과정이 요구되며, 이는 훈련을 통해 이루어질 수 있다.
음도 조절은 주로 내후두근(intrinsic laryngeal muscles), 특히 윤상갑상근(cricothyroid muscle)과 갑상피열근(thyroarytenoid muscle)의 조절 및 공기역학적 요인에 의해 이루어진다(Choi et al., 2006; Tanaka & Tanabe, 1989). 흉성구에서 가성구로의 성구전환은 음원에서 고주파 소리의 에너지를 얻거나 상실했을 때 초래되는 갑작스러운 음질의 변화로 이 지점에서 강도가 급격하게 감소하게 되는데, 이는 내후두근의 조절능력에 따른 성문의 폐쇄 정도에 의해 영향을 받기 때문이다. 주요한 성구전환에 의한 음질 변화는 불수의적(involuntary)으로 발생하며, 대개 300–350 Hz에서 나타난다. 남성에서는 이 주파수 범위가 두 번째 성구전환(2ndPASSAGGIO)이 발생하는 지점으로 훈련된 성악가에 있어서는 성구전환이 두드러지지 않고 넓은 기본주파수 범위에 걸쳐서 균일한 음질이 산출된다. 다만 수의적(voluntary) 음질 변화는 성대 내전의 변화와 호흡 압력변화에 의해 조절될 수 있기 때문에 발성이나 호흡 훈련 정도에 따라 성구전환 시 음질의 변화가 다르게 나타날 수 있다.
모음에 따라 F0MAX와 F0RANGE의 차이가 있지만 대상자의 발성조절능력에 따라 모음 간에 차이가 나타나지 않을 수도 있다. 가령, 테너 성종에서 한 대상자는 모든 모음의 F0MAX가 C5 (523.25 Hz), F0MIN은 A#2(116.54 Hz)로 모음 간에 음역의 차이가 없는 반면, 테너 성종의 다른 대상자는 모음 /a/, /i/, /u/의 F0MAX가 각 E5(659.25 Hz), A4(440.00 Hz), C5(523.25 Hz), F0MIN은 B2(123.47 Hz), A2(110.00 Hz), A2(110.00 Hz)로 모음에 따라 상당히 다른 F0MAX와 F0MIN을 산출하였다. 같은 모음에서도 강하게 산출하는 발성과 약하게 산출하는 발성 간의 음역 차이가 나타났는데, 모음 /a/를 강하게 발성했을 때는 F0MAX가 E5, 약하게 발성했을 때 F0MAX가 G#5로 이들 간의 차이가 네 반음 이상으로 나타났다. 즉 대상자의 발성조절 능력에 따라 모음 간에 음역이 다를 수 있다. 본 연구에 참여한 대중가요 보컬 전공생이나 입시생 중에서 충분한 훈련을 받은 경우도 있지만 그렇지 않은 경우도 있다. 발성을 조절할 수 있는 능력이 미숙한 보컬의 경우 흉성에서 가성으로 전환되는 고음역 구간에서 후두의 상승을 조절하지 못하거나 공기역학적 기전을 조절하지 못해 성대의 충분한 내전을 형성하지 못함으로써 고음을 산출하지 못할 수 있다(Neumann et al., 2005). 즉 동일한 성종 내에서도 발성조절능력에 따라 모음별로 산출할 수 있는 음역의 차이가 있음을 시사한다.
다섯째, 각 모음별 성종 간 음역을 비교한 결과, 모음 /i/의 F0MIN와 F0HEAD 및 모음 /u/의 F0HEAD를 제외한 모든 모음의 음역 변수에서 성종 간에 유의한 차이가 있었다. 모음 /i/와 /u/에서 2ndPASSAGGIO부터 F0MAX까지의 범위인 F0HEAD는 성종 간에 유의한 차이가 없었는데, 고음역, 특히 가성구에서는 앞에서 언급했던 성도의 모양을 조절하는 포먼트 튜닝 과정과 성대를 내전하는 근육들의 상호작용이 고음을 산출하는데 중요한 역할을 한다. 흉성구에서는 F0가 상승함에 따라 성대 길이가 증가하면서 성대의 긴장성이 증가하지만 가성구에서는 F0가 상승해도 성대 길이의 변화가 크지 않다(Choi et al., 2006). 즉 가성구나 두성구에서는 음도 조절이 성대 길이의 변화에만 의존하지 않는다는 것이다. 모음 /i/와 /u/는 앞에서 설명한 바와 같이 고모음으로 고음역을 산출하는데 어려움이 있으며, 가성구의 범위 또한 모음 /a/에 비해 제한적일 수밖에 없다. 또한 본 연구는 발성이나 호흡 훈련이 충분히 이루어지지 않은 전공생이나 입시생을 대상으로 하였기 때문에 성종에 상관없이 가성구의 고음역을 산출하는데 더 많은 제한이 있다고 볼 수 있다. 모음 /a/는 가성구를 포함한 고음역에서 /i/나 /u와 같은 고모음에 비해 후두의 상승이나 인두강 면적의 조절이 용이하므로 보다 고음역을 산출하기 쉬운 테너의 성종에서 가성구의 범위가 더 넓은 것으로 보인다.
저음에서는 고음과 반대로 음이 내려갈수록 후두도 같이 하강하게 된다. 전설고모음인 /i/를 정조음하기 위해서는 음도가 하강하더라도 혀의 위치가 상승된 상태를 유지해야 하므로 성종에 상관없이 후두의 하강이 제한적일 수밖에 없다. 모음 /i/의 F0MIN은 성종 간에 차이가 없었던 것으로 보인다.
여섯째, Nam & Choi(2007)와 Titze(2000)가 제시한 음역 구분의 기준인 표 2를 보면, 각 성종별로 2옥타브 정도의 음역을 산출할 수 있다. 본 연구의 F0MAX–F0MIN은 모음 /a/에서 테너는 121.33–642.20 Hz, 바리톤은 112.88−448.11 Hz, 베이스는 97.33– 349.00 Hz로 표 2에서 제시한 음역과 유사한 결과를 보였다. 다만, 본 연구의 바리톤과 베이스의 경우 표 2에 제시된 F0MAX–F0MIN에 비해 좀 더 높은 수치를 보였는데, 이는 성종에 상관없이 대중가요 보컬은 국내 대중가요의 주를 이루는 음역인 C3–C5를 주로 연습하기 때문에 본인의 성종에 적합한 음역보다는 높은 음역을 산출하는 것으로 보인다. 대중성이 높은 음악인 방탄소년단의 ‘다이너마이트’나 멜로망스의 ‘선물’을 살펴보면, 주로 C3–C5의 음역으로 구성되어 있다. 다른 많은 대중가요 또한 이 음역에서 노래가 이루어진다. C3–C5의 음역은 주로 테너가 산출하기에 적합한 음역으로 베이스의 성종을 가진 보컬이 노래하기에 매우 어려운 음역이다. 테너의 성종인 대중가요 보컬 전공 남성의 경우 다른 성종에 비해 대중가요 음계에서 선호하는 고음역의 산출을 용이하게 하기 위해 자신의 발음이나 발성, Passaggio 구간에서의 문제점을 개선해 가면서 실력을 쌓아갈 수 있다. 반면, 베이스나 바리톤의 성종인 경우 고음역의 음악으로 구성된 대중가요를 노래하기 위해서는 본인의 음역을 확장하거나 높여야 하며, Passaggio 구간을 음도일탈 없이 부드럽게 산출하는 훈련 과정이 필요하다. Neumann et al.(2005)은 성종의 따라 중간 음역에서 높은 음역으로 바뀌면서 음색이 변하는 성구전환, 일명 Passaggio 구간의 횟수가 달라질 수 있다고 하였다. 테너는 1–3회 정도의 성구전환 과정을 거치는 반면, 바리톤이나 베이스는 2–3번의 성구전환 과정을 거친다. 고음역에서 성구전환 구간을 해결하기 위해 포먼트 튜닝 과정이 필요하다(Bozeman, 2013; Lehoux et al., 2022; Neumann et al., 2005; Schutte & Miller, 1984; Titze, 2008; Titze & Worley, 2009).
본 연구결과를 종합해 보면, 대중가요 보컬을 전공하거나 입시를 준비하는 남성의 절반 이상이 본인의 성종을 정확하게 파악하지 못하고 있으며, 모음 간에 F0MAX와 F0RANGE는 통계적으로 유의한 차이를 보여 모음의 종류에 따라 산출할 수 있는 음역의 차이가 있음을 알 수 있었다. 특히 모음 /a/>/u/>/i/ 순으로 음역이 감소하는 것을 확인할 수 있었는데, 모음 /a/는 고음역에서 조음하기에 용이하므로 대중가요 보컬을 배우는 남성이 고음역을 연습하는데 사용하기 유리한 모음인 반면, 모음 /u/와 /i/는 고모음으로 혀의 위치가 상승함으로써 구강 면적이 좁아지고 후두의 상승이 동반되기 때문에 고음을 발성하기에 어려움이 초래된다는 것을 알 수 있다. 또한 모음별로 구분하여 성종 간에 음역을 비교하였을 때 대부분의 음역 변수에서 유의한 차이를 보여 모음의 종류와 상관없이 성종 간에 산출할 수 있는 음역의 차이가 있음을 보여준다.
최근 대중음악의 높은 인기로 인해 이를 전문적으로 배우고자 하는 사람이 증가하고 있으며 일반인들의 취미생활로 노래에 대한 관심이 높아지고 있다. 대중가요의 전달력과 호소력의 특성상 고음역의 노래가 많아 본인이 산출할 수 있는 음역에 대한 기본지식이나 충분한 훈련 없이 무리하게 고음역을 연습할 경우 후두의 손상을 초래할 수 있다. 말소리를 정확하게 정조음하지 않고 공명강을 효율적으로 사용하여 소리를 전달하는 성악가와는 다르게 대중가요 가수는 또렷한 발음과 가사전달력이 요구된다. 고음역의 음계가 많이 사용되는 대중가요의 특성상 대중가요 가수는 고음역에서도 모든 음소를 정확하게 조음해야 한다. 그러나 본 연구에서 밝힌 바와 같이 모음에 따라 산출할 수 있는 음역의 차이가 있으며, 성종에 따라서도 산출 가능한 모음의 음역이 다를 수 있기 때문에 본인의 성종에 부합하는 음역의 노래를 선정하고 노래 가사 또한 본인이 산출할 수 있는 범위에 있는지를 판단할 필요가 있다. 본인의 성종에 부합하지 않는 노래를 반복적으로 연습하고 부르게 되면 음성문제가 초래될 가능성이 매우 높기 때문이다.
본 연구는 대중가요를 전공하는 전공생과 입시생을 대상으로 성종과 모음에 따른 음역을 비교함으로써 대중가요 보컬을 전공하거나 입시를 준비하는 남성이 자신의 산출 가능한 음역을 좀 더 인지하고, 모음에 따라 산출할 수 있는 음역이 무엇인지를 파악하여 무리하게 고음역을 산출하는 음성 오·남용을 방지할 필요가 있음을 제시하였다.
대중가요를 대상으로 한 연구 자료가 부족하여 상대적으로 연구 자료가 많은 성악 분야 연구를 참고하였다. 성악과 대중가요는 발성 양상이 다르기 때문에 성악가 집단의 성종을 대중가요 보컬 전공자들에 직접 적용하는 것이 바람직하지 않을 수 있다. 또한 본 연구의 성종별 대상자의 수가 고르게 분포하지 않아 성종에 따른 집단 간의 차이를 보다 정확하게 살펴보기 어려웠다. 이에 추후 연구에서는 성종별로 좀 더 많은 대중가요 보컬을 대상으로 성종 간의 생리학적, 음향학적 차이를 비교할 필요가 있다. 본 연구는 남성만을 대상으로 음역을 살펴보았기에 본 연구의 결과를 대중가요 가수 전반에 걸쳐 일반화하기 어렵다. 추후에는 대중가요 여성 보컬 가수나 전공생을 대상으로 본인의 음역을 파악하고 있는지, 실용음악 전공생과 입시준비생 간에도 차이가 있는지, 그리고 모음에 따른 음역의 차이가 있는지도 함께 살펴보아야 할 것이다. 본 연구는 대중가요 가수와 같은 전문적 음성사용자가 자신의 음역을 제대로 알고, 가사에 따라 산출 가능한 음역의 차이가 있음을 파악하여 본인에게 적합한 음역의 노래를 선곡할 필요가 있음을 제시하였다. 이를 통해 대중가요 가수나 전공생 또는 입시생이 무리하게 고음역을 산출함으로써 발생할 수 있는 음성 오ㆍ남용을 방지하는데 도움이 될 수 있을 것이다.