





1. Introduction
Although North and South Korean language are mutually intelligible and use the same Korean alphabet, called “Hangeul”, linguistic divergence between the two countries has been observed. 74 years of territory separation and different language policy have been considered the primary factors of this linguistic divergence (Sohn, 2001). One of the linguistic differences between North and South Korean has been prominently observed in vowel production (Kahng, 1999a, 1999b; Kang, 1996, 1997; Kang & Yun, 2018; Lee, 1990, 1991; Lee et al., 2018). The current study examines the phonetic characteristics of standard varieties of North (NK) and South Korean (SK) by comparing vowel production in both careful and conversational speech contexts.
Traditionally, before the Korean War in 1950, when Korea was a united country, Korean monophthongs included ten vowel types: [i], [e], [æ], [ʌ], [o], [ɯ], [u], [a], [y], and [ø] (Korean Language Association, 1933; Sin et al., 2012; Umeda, 1999). However, diachronic changes in cardinal vowel production in SK have been actively documented and the monophthong changes often vary dynamically across generations (Han & Kang, 2013; Jang & Jiyoung, 2006). For instance, younger speakers tend to exhibit a [o]–[u] and [e]–[æ] merger in a more progressive manner than older generations, reflecting ongoing sound changes where distinctions between certain vowels are gradually diminishing. Previous studies suggested that patterns of monophthong variation and the process of sound change differ based on age and generation. As vowel production appears to vary across generations, this study focuses primarily on younger speakers in their 20s and early 30s to capture these changes in their contemporary form.
From around 1990, it has been noted that, in SK, [y] and [ø] were diphthongized to [wi] and [wɛ], respectively. In addition, from around 1990, [e] and [æ] have been now in complete merger as [ɛ] in both production and perception, at least more prominently in younger SK generation (Sin et al., 2012; Umeda, 1999). Thus, the number of SK cardinal vowels are now considered seven ([i], [ɛ], [ʌ], [o], [ɯ], [u], [a]) (see Table 1 and Sin et al., 2012).
| Backness | Front | Back | |
|---|---|---|---|
| Roundness | Unrounded | Unrounded | Rounded |
| High | i | ɯ | u |
| Mid | ɛ | ʌ | o |
| Low | a | ||
In addition to the merger of [e] and [æ], recent changes in [o] and [u] production have been reported. After around 2000, in SK, it has been observed that [o] and [u] are approximated in younger female speakers (e.g., Han & Kang, 2013; Seong, 2004), with [o] raised to the space of [u]. More recently, after 2010, a new trend of vowel production has been reported in Kang & Kong (2016) and Lee et al. (under review). They suggested a chain shift following the raising of [o]. The raising of [o] signals that the idea was already introduced. Specifically, in Lee et al. (under review), [o] and [u] are no longer in approximation but now are well-distinguished in different phonemic space. In their findings, [u] was produced in more fronted and higher position than [o], and the separation of [u] from [o] was more advanced in the conversational speech than in careful speech (Lee et al., under review). Their study demonstrated a possibility of broader vowel chain shift as an ongoing sound change, also involving the lowering of [ɯ] and raising of [ʌ] in conversational speech (Lee et al., under review).
In contrast to the vast body of SK vowel research, NK has little been examined so far to our knowledge. Lee (1991) first attempted to study NK vowels. Unlike SK vowels, he reported that NK vowels still preserve the ten cardinal vowels ([i], [e], [æ], [ʌ], [o], [ɯ], [u], [a], [y], and [ø]). In his study, vowels were typically described in terms of vowel height, backness, and lip roundness. And the backness dimension was typically divided into three: front, center, and back. Lee (1991) also used height, backness, and roundedness. However, the backness has 4 categories (tip, front, center, back) in Lee’s analysis rather than our usual 3 (front, center, back). Thus, vowels were classified with four different parameters of tongue backness, including the tongue tip. Specifically, vowels were classified with kkuthmoum: end of tongue tip, aphmoum: tongue in front, kawunteymoum: tongue in middle, and twimoum: tongue in back of articulator. In addition, NK vowels were sorted by shape of mouth and height of tongue. They have named unrounding vowels as kilccukmoum: flat vowels and rounding vowels as twungkunmoum: round vowels (Lee, 1991). In terms of vowels with tongue height, they did not have mid vowels but only had high and low vowels (Lee, 1991). The vowel inventory of NK is shown in Table 2.
| End of tongue tip | Front | Center | Back | |||
|---|---|---|---|---|---|---|
| Roundness | Flat | Flat | Round | Flat | Flat | Round |
| High | [i] | [e] | [y] | [ɯ] | [ʌ] | [u] |
| Low | [æ] | [ø] | [a] | [o] | ||
Thus, NK monophthongs include four vowels of [ø], [y], [æ], and [e] that were only included in SK in the past. In his argument, [y] and [ø] are still monophthongs in NK. In addition, unlike SK vowels, [e] and [æ] are still distinguished in NK (Lee, 1991). If his findings are correct, NK still preserves the conservative ten vowel system in 1933. More importantly, recall that while [ʌ] is a mid-back vowel in SK, [ʌ] is a high back vowel in NK. If this description is accurate, NK has a very crowded vowel space for high vowels. However, considering the year of publication (Lee, 1991), and the fact that there were no acoustic data in his studies, it is unclear whether NK vowels still have the old conservative ten vowel system. Moreover, it is also unknown whether vowel sounds of NK monophthongs have changed.
More recently, Morgan (2015) and Lee et al. (2018) empirically analyzed NK vowels. Morgan (2015) measured first formant (F1) and second formant (F2) of vowels, using speech data in movies filmed between 1950 and 2010 in both NK and SK. Lee et al. (2018) compared read and natural speech production between NK and SK newscasters and regular NK refugee speakers and SK speakers.
Both studies reported back vowel mergers in NK. First, the NK [ʌ] and [o] were articulated in a similar position. In addition, the NK [ɯ] and [u] were also produced in similar position. Thus, the findings raised a possibility of back vowel mergers in NK ([ʌ] as [o] and [ɯ] as [u]). More specifically, in Lee et al. (2018), the degree of vowel merger was quantified using the Pillai score, where lower values indicate a greater degree of merger (see Hall-Lew, 2010 for details). The results showed that the [ɯ]–[u] contrast was more merged in NK speakers (Pillai score: 0.348) compared to SK speakers (Pillai score: 0.440). Similarly, the [ʌ]–[o] contrast was also more merged in NK (Pillai score: 0.233) than in SK (Pillai score: 0.486). However, the [e]–[æ] contrast exhibited the opposite pattern, with a greater degree of merger in SK (Pillai score: 0.029) than in NK (Pillai score: 0.158, see Lee et al., 2018 for more information). Thus, the distinction of [e] and [æ] and mergers of [ʌ]–[o] and [ɯ]–[u] in NK might indicate noticeable differences in vowel production between NK and SK.
In addition to the standard variety spoken in North Korea, several studies have explored vowel production in non-standard North Korean dialects. While our study primarily focuses on the standard varieties in both North Korea and South Korea, we provide an overview of previous research on vowel production in the Hamkyong dialect below. For example, Lee & Ramsey (2000), Kahng (1999a, 1999b) and Kang (1996, 1997), examined vowel production in Hamkyong and Hwanghae dialects (northern eastern and southern western province, respectively). Similar to the findings in NK, they also reported that Hamkyong and Hwanghae North Korean dialects may still preserve the traditional ten cardinal vowels, including [y], [ø], [e] and [æ]. In addition, similar to NK, Kang also claimed that the [ʌ] and [ɯ] were merged to [o] and [u], respectively in Hamkyong North Korean Kahng (1999a, 1999b), (Kang, 1996, 1997).
More recently, Kang & Yun (2018) compared vowel production between Hamkyong North Korean dialect and SK. Their findings were consistent with the previous literature Kahng (1999a, 1999b), (Kang, 1996, 1997). In reading word tasks, Kang & Yun (2018) articulated [ɯ] in a more backed position, which was close to the position of [u]. In addition, the Hamkyoung [ʌ] was produced in a higher and more fronted position than the SK [ʌ], which was close to [o]. Moreover, similar to the previous results, the Hamkyong speakers distinguished between [e] and [æ] unlike the SK [e] and [æ] were merged into [ɛ] position.
Previously, it seemed that some vowel contrasts ([e]–[æ], [ɯ]–[u], [ʌ]–[o], and [o]–[u]) might show noticeable differences in North and South Korean. However, Lee (1991) and studies of Kang (1996, 1997) did not provide empirical data to support their claims. Speech data of Morgan (2015) was from the films, rather than natural conversational speech. Moreover, Lee et al. (2018) included a small number of speakers (each of two newscasters in North and South Korea and each of two speakers in North and South Korea). In addition, the results of Kang & Yun (2018) were limited to nonstandard North Korean dialect in read speech. Thus, there has been little comparison between standard varieties of North and South Korean, examining both read (careful) speech and conversational speech. It has been well-documented that speakers often switch their production depending on speech styles. Specifically, speakers tend to produce more conservative and formal style when they can pay attention to their own speech (e.g., read speech, Labov, 2006). In contrast, in conversational speech, they often produce more casual and vernacular styles because they cannot monitor their production (Labov, 2006). More importantly, given that North Korean accents are often judged negatively and stigmatized in South Korea and North Korean refugees are more likely to be discriminated because of their accents (e.g., Kim & Jang, 2007; Park & Ahn, 2009), it is possible that they might switch their pronunciation more sensitively, depending on the speech conditions. First, it is possible that they may monitor their production more extensively, showing more SK-like vowel production in careful speech. On the other hand, there is also a possibility that they may try to speak more like SK in conversational speech when they converse with the first author (SK speaker). They may change their production and try to converge their manner of pronunciation to be more like the interlocutor (see communication accommodation theory, Giles, 1980). Based on this, we hypothesize that the effects of speech condition might be significant on the vowel production of NK more extensively. Thus, our study can capture more insightful dynamics of NK production, by investigating their speech in both speech conditions.
We compare NK and SK vowels in both careful and conversational speech, focusing more on the particular vowel types ([e], [æ], [ɯ], [u], [ʌ], and [o]). Given that previous literature has documented phonetic differences between SK and NK vowel production, in our hypotheses, the NK [e]–[æ] might still be differentiated, unlike the SK counterparts. In addition, the NK speakers might also show the mergers in back vowels ([ɯ] as [u] and [ʌ] as [o]). However, more importantly, again we hypothesize that the vowel production might be different across the speech conditions. Specifically, the degree of distinction between [e] and [æ] and the degree of mergers ([ʌ]–[o] and [ɯ]–[u]) might differ. It is possible that the NK speakers may show merger between [e] and [æ] in conversational speech but less merger of the back vowels to speak more like SK in the conversation with the SK speaker. Through the comparison, we aim to report the acoustic differences between NK and SK vowels produced by younger speakers in their 20s and 30s, focusing on style shifts among NK speakers. Additionally, by providing spoken data on NK vowel production, our goal is to contribute to NK refugees’ SK vowel acquisition as part of second dialect acquisition.
2. Methodology
Twenty-two each of SK speakers and NK speakers (16 females and 6 males for each) participated. Both NK and SK participants were recruited through personal networks and by word of mouth, and they received compensation for their time. First, the experimenter (the first author) had developed a strong rapport with the NK speakers prior to data collection, having volunteered for nine years at a government center that assists in the settlement of North Korean refugees. The NK participants were recruited through the first author’s personal connections. In addition, the SK speakers were recruited at H University in Seoul where the first author has strong personal connections. Thus, all NK and SK speakers interacted comfortably with the first author in the conversational condition. The session included both a reading task and a sociolinguistic interview.
The speakers’ demographic information was collected during the sociolinguistic interviews, and responses are summarized in Table 3. All SK participants were in their 20s and early 30s at the time of testing and were born and had lived in Seoul for their entire life. All of the NK speakers were from Pyongyang province, in towns near Pyongyang, the capital city of North Korea, a region whose variety is considered standard (Sohn, 2001). All NK speakers reported speaking Pyongyang standard language while living in North Korea. Age of arrival (AoA) and length of residence in Seoul (LoR) varied among the NK speakers (AoA: 9 to 31, LoR: 1 to 10). As for their education level, four NK speakers graduated from college in Seoul and have worked in Seoul, and eighteen NK speakers attended a high school for North Korean students in Seoul. All NK speakers arrived in SK after the early 2000s, after the [e]–[æ] merger and diphthongization of [y] and [ø] in SK (e.g., Sin et al., 2012).
All participants completed the reading task before the interview task. The reading task elicited the eight cardinal vowels ([i], [e], [æ], [ɯ], [ʌ], [o], [u], [a]). In reading task, speakers were asked to produce the syllables in a carrier sentence “___ (la)ko malha-yss-ta (I said____ )” (Kang & Guion, 2008, 2009).
Each speaker sat in front of a laptop computer, wearing a lavalier microphone Audio-Technica AT 899 (Audio-Technica, Leeds, UK), which was connected to a Marantz PMD 670 (Marantz, Eindhoven, NL, USA) flash drive recorder. Speakers completed the reading task first, followed by the interview task. The computer screen presented each syllable (V) in the carrier sentence in three randomized orders. Speakers were instructed to read aloud each item carefully. They each produced 24 utterances in total (8 vowels×3 repetitions). These tasks took approximately ten minutes to complete.
Immediately following the reading tasks, the participant and the first author engaged in a sociolinguistic interview over approximately 45 minutes, eliciting between 656 to 1,660 vowels from each speaker, for the total of 13,370 vowels. In the sociolinguistic interview, the participant and interviewer sat face to face, and the same recording device described above was used for this task. The interview questions were modified from sociolinguistic interview questions intended for immigrant population developed by Anastassiadis et al. (2017). Two sets of interview questions were developed, one for NK refugee speakers and the other for SK speakers. The demographics section of the interview included questions about their name, age, hometown, AoA, and LoR in SK. The SK and NK topics asked questions regarding their lives, neighborhood, people, and language in each region. All participants answered all questions in the interview. The speech collected in this task was spontaneous and conversational, using honorific speech (contaymal, polite formal speech) form in Korean (Brown, 2015; Winter & Grawunder, 2012).
All vowels in the reading and conversational speech analyzed here were content words in IP-initial positions. Following the convention from previous studies (Jun, 2000), the first author identified the vowels in IP-initial positions in both speech tasks. In addition, given that following consonant of the vowel (coda) can influence the vowel production (c.f., coarticulatory effects, Luce & Charles‐Luce, 1985; Van Summers, 1987), we only analyzed the vowels that were produced without coda in conversational speech.
We focused on analyzing vowels in IP-initial positions because these positions are less likely to be influenced by preceding prosodic context, allowing for a clearer examination of vowel characteristics (Jun, 2000). Additionally, given that the coda consonants can influence vowel production (e.g., coarticulatory effects, Luce & Charles‐Luce, 1985; Van Summers, 1987), we only analyzed vowels without a coda in conversational speech to minimize this effect. Recall that the target vowels in reading condition were in a (V) structure, without onset and coda. For the conversation task, we included the onset consonants preceding the target vowels to account for their potential influence on vowel production. All the information on other preceding consonants can be found on the osf link (https://shorturl.at/bTd7u).
The first author identified the vowel types in the first syllable of content words in conversational speech and manually segmented the vowels. The first and second formants (F1 and F2) in the vowels were measured at the mid-point of each vowel. The total number of vowels analyzed was 13,370 (NK: 9,035, SK: 4,335 vowels, respectively). Each vowel was coded for the syllable and the preceding consonant, as well as the task (i.e., careful and conversation). The vowels in careful and conversational speech were identified and segmented, which is also available on the osf (https://shorturl.at/bTd7u).
First, for visual presentation, raw F1 and F2 values were normalized using the Lobanov normalization method as implemented in the Vowel package (Kendall & Erik, 2020) in the R environment (R Core Team, 2023) to control for speaker gender. Next, we ran mixed effects linear regression (Baayen et al., 2008) accounting for formant values (F1 and F2) as implemented in the lme4 package (Bates et al., 2015) in the R environment (R Core Team, 2021), to focus on the vowel production depending on the speaking condition across NK and SK. The models (1) and (2) included as fixed effects Dialect (NK, SK, categorical factor, treatment coded, SK as a reference), Vowel ([i], [e], [æ], [ʌ], [o], [ɯ], [u], [a], categorical factor, treatment-coded, [a] as a reference), Speech condition (careful and conversation, treatment-coded, careful as a reference), and the three-way interactions among the three factors. All models included a random intercept for Preceding consonant, as it was possible that dependent measures varied due to the context of preceding consonant. A random intercept for Speaker was also added to account for individual variations in the dependent measures. All models included a random slope for Vowel by Speaker because by-speaker variation in the dependent measures could be conditioned by Vowel type. Vowel and Speaker in the random effects were uncorrelated to aid convergence. Statistical codes and results for the models are also shared on osf (https://shorturl.at/bTd7u).
3. Results
We present vowel production in each speech condition separately. First, Figure 1 plots all vowels in careful speech of NK and SK. The visual inspection of the plot indicates that some of our target vowels ([e], [æ], [ʌ], [o], and [u]) appear to have different distributions across NK and SK in careful speech. First, unlike the previous findings that showed [ɯ]–[u] approximation in NK (e.g., Kang & Yun, 2018; Lee et al., 2018), our plots indicated that the NK [ɯ] seemed to be produced in a similar position to the SK [ɯ] (mid-high position). Thus, it seemed that [ɯ] and [u] are well-distinguished in NK. Next, similar to the findings in previous studies, [e] and [æ] appeared to be more distinguished in the NKs’ production (Lee, 1991; Lee et al., 2018). In contrast, the vowel space of [e] and [æ] seemed to be overlapped completely in the SKs’ production. In addition, consistent with the previous findings (e.g., Lee et al., 2018), the vowel [ʌ] was produced in a closer space to [o] in NKs’ speech, compared to SKs’ speech. More importantly, from the visual inspection, [o] and [u] were still maintained its phonemic space in the NK’s production, indicating [u] as high-back vowel and [o] as mid-back vowel while [o] was produced in high position, which was closer to [u] in the SKs’ production.
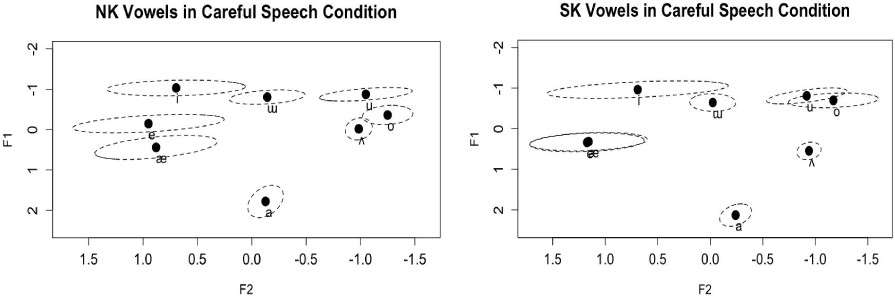
Next, Figure 2 schematizes the vowels in conversational speech of NK and SK. First, in both NK and SK, unlike the Figure 1, it seems that the distance between [ɯ] and [u] was closer in conversational speech. Recall that previous literature reported that [ɯ] was more backed in NK (thus, closer to [u]; e.g., Lee et al., 2018). However, unlike the previous demonstration, the distance between [ɯ] and [u] appears closer in the current data because [u] is produced in a more fronted position, rather than the retracted position of [ɯ].
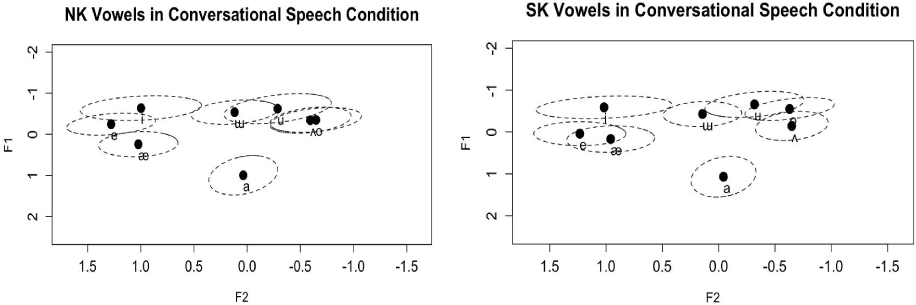
From the visual inspection, the phonemic spaces of [ɯ] and [u] overlapped because of [u] fronting. Next, consistent with the patterns in Figure 1, [e] and [æ] still appeared to be distinguished in conversational speech of NK. Moreover, in NK, it seemed that [ʌ] and [o] overlapped more in conversational speech than in careful speech.
In terms of SK, unlike the patterns in careful speech, it was noteworthy that [e] and [æ] appeared to be distinguished in the backness dimension in conversational speech. Specifically, Figure 2 indicates that [e] is more fronted than [æ]. In addition, the SK [ʌ] also seemed to be more overlapped with the space of [o] in conversational speech than in careful speech, similar to the pattern of NK [ʌ]. Furthermore, [u] appeared to be produced in higher and more fronted position in conversational speech than in careful speech, consistent with the previous findings (e.g., Lee et al., under review).
In conversational speech, similar vowel patterns were observed between NK and SK. It appears that both NK and SK speakers separated phonemic space of [e] and [æ] in conversational speech. However, while the NK speakers distinguished the [e]–[æ] in the height dimension, the SK speakers seemed to distinguish the pair in the backness dimension. Moreover, [u] was more fronted in both NK and SK. Also, the phonemic space of [ʌ] and [o] seemed to be more overlapped in both NK and SK, comparing to the production in careful speech.
Figures 1 and 2 showed that NK and SK vowels were majorly different in terms of phonemic spaces of the following five vowels ([e], [æ], [ʌ], [o], [u]). In addition, the plots raised a possibility that both NK and SK vowel productions might have been influenced by speech conditions. To confirm these observations, we present detailed statistical analyses.
We ran mixed effects regression models i.e., Models (1) and (2) to compare the vowels ([i], [e], [æ], [ʌ], [o], [ɯ], [u], [a]) between NK and SK in both careful and conversational speech. The results of Model (1) and (2) are summarized in the appendix (Appendix 1).
First, the F1 model results (Appendix 1) indicated significant effects for all vowel types, demonstrating that the tongue height of the seven vowels ([i], [e], [æ], [ʌ], [o], [ɯ], [u]) differed from that of the reference vowel [a], as anticipated. For example, the vowel [i] showed a significant difference in tongue height compared to [a] (β= –505.83, CI=–542.10−–469.55, p<.001).
Moreover, the main effect of speech condition was significant (β= –171.49, CI=–205.71−–137.27, p<.001). In other words, the reference vowel [a] was produced in higher position in conversational speech than in careful speech.
More importantly to our research question, Vowel type production was significantly influenced by Dialect. We found that the NK [e] was produced in a significantly higher position than the SK [e] (β=–65.93, CI=–117.64– –14.22, p=.012). In addition, the NK [ʌ] was produced in a significantly higher position than the SK [ʌ], indicating the raising of [ʌ] in NK (β=–71.07, CI=–126.23– −15.92, p=.012). Moreover, the NK [o] was produced in a significantly lower position than SK [o] (β=75.55, CI=19.11–132.00, p=.009). Thus, unlike the SK, [o] still maintained its mid-back position in NK. These findings confirm our visual observations in Figures 1 and 2.
Next, significant interactions between all Vowel type and Speech condition were also examined. Specifically, conversational speech condition affected all the vowels to be lowered (e.g., Vowel [i] × Conversational speech: β=244.68, CI=205.15–284.20, p<.001). More importantly, we hypothesized that vowel production might be different across speech conditions in NK and SK. However, there was no three-way interactions (Dialect × Vowel type × Speech condition) in the F1 dimension, suggesting that the height of vowels was consistent across the speech conditions in both NK and SK.
Given that the two-way interactions were significant, in order to confirm the acoustic differences in NK and SK vowels, we examined whether F1 distinguishes the specific vowel types, focusing on each vowel contrast ([e]–[æ], [ʌ]–[o], [ɯ]–[u], and [o]–[u]), by conducting post-hoc test comparing the mean F1 values for these contrasts in each of the Dialect groups separately. The results from post-hoc analyses are presented in the next paragraph.
Because the focus of the current analysis was, primarily, whether F1 distinguishes each vowel contrast, we conducted the first set of post-hoc tests comparing the mean F1 values for these contrasts in each of the Dialect groups separately. The first post-hoc results are presented in Appendix 2.
In the F1 dimension, starting with the NK speakers’ production, [e] and [æ] was significantly differentiated (β=80.26, SE=12.5, z=6.439, p<.0001). Thus, given that NK speakers still distinguish [e] and [æ], it is confirmed that NK vowels have not undergone [e]–[æ] merger, unlike SK. Presumably, the [e]–[æ] production might be close to the patterns that were observed before 1990 in SK. Next, while they did distinguish the height of [e] and [æ], they did not differentiate the height of [ʌ] and [o] (β=–35.04, SE=14.22, z=–2.534, p=.1811). The findings indicate that [ʌ] and [o] are approximated in NK, by supporting the previous findings that reported the noticeable overlap between [ʌ] and [o] (e.g., Lee et al., 2018). In terms of [ɯ]–[u] in NK, the merger of the pair has solely reported in the backness dimension. In other words, both [ɯ] and [u] are produced in high position, which was also supported in our findings (β=–25.52, SE=12.3, z=–2.079, p=.04289). Finally, for the [o]–[u] contrast, the vowels were well-distinguished in F1 dimension (β=78.1, SE=13.77, z=5.67, p<.0001), indicating that [o] as a mid-vowel and [u] as a high vowel in NK. Thus, unlike the SK [o]–[u] in previous studies (e.g., Kang & Kong, 2016), in NK, [o] and [u] still preserve its original position in NK, at least in the F1 dimension. Our results extend the findings of previous research: in NK, [e] and [æ] are well-distinguished while [ʌ] and [o] are not differentiated in the F1 dimension. More importantly, [o] and [u] still maintained its own phonemic space at least in the F1 dimension, [o] as a mid-vowel and [u] as a high vowel.
Next, the results of SK speakers are presented in Appendix 3. The SK speakers’ vowel production looked different from those of NK speakers. The [e]–[æ] contrast was not differentiated in the F1 dimension (β=8.89, SE=13.1, z=0.679, p=.9975). Whereas [ʌ]–[o] contrast was significantly distinguished (β=–139.4, SE=14.4, z=–9.666, p<.0001), [o]–[u] contrast was not distinguished (β=17.85, SE=13.9, z=1.287, p=.9038), suggesting overlap of [o] and [u] in the F1 dimension. Thus, consistent with the previous findings (e.g., Kang & Kong, 2016), the SK [e]–[æ] contrast is not distinguished in the height dimension. Also, the SK [o] is produced in a higher position, invading the original position of [u]. Unlike NK, the SK [ʌ]–[o] contrast is well-distinguished in the F1 dimension.
Next, the second set of post-hoc pairwise tests comparing NK and SK revealed significant differences for F1 in vowel production. The post-hoc results are presented in Appendix 4. In comparison between NK and SK, the NK [æ] was produced in a significantly lower position than the SK [æ] (β=–55.9, SE=19.2, z=–2.913, p=.0036). Given that the height of [e] was not different between NK and SK (β=15.4, SE=16.4, z=0.944, p=.3452), the lower tongue height of [æ] may mark one of the major acoustic features of NK vowels. In addition, the height of [o] was significantly different between NK and SK. Next, the NK [o] was significantly lower than the SK [o] (β=–83.7, SE=19.4, z=–4.322, p<.0001). This confirms that, unlike the SK [o], the NK [o] still maintains its mid-high position while the SK [o] raised up to the high vowel position. This contrasts with Lee’s (1991) description, where [o] was categorized as a low vowel; in the current data, however, [o] was produced in a mid-high position. Recall that [ʌ] and [o] were close to each other in the F1 dimension in NK, the approximated height of [ʌ]–[o] may also represent NK feature of vowel production. To sum up, given that the height of [æ] and [o] was significantly different between NK and SK, NK manner of [æ] and [o] production might represent major acoustic differences.
Next, for the F2 model, apart from [ɯ], the Vowel type effects were significant for the six vowels, indicating that the tongue backness of the six vowels ([i], [e], [æ], [ʌ], [o], [ɯ]) was different from the backness of the reference vowel [a] (e.g., Vowel [i]: β=506.86, CI=363.23–650.49, p<.001; see the Appendix 1). Recall that both [a] and [ɯ] were categorized as mid-vowel in SK while [a] was a back-vowel and [ɯ] was a center vowel in NK (Lee, 1991; Sin et al., 2012). Although [ɯ] and [a] were categorized differently in NK and SK, the backness between the two vowels ([ɯ] and [a]) were not different from each other in current findings.
More importantly to our research question, Vowel type production was influenced by Dialect in the F2 dimension. We found that both [e] and [æ] in NK were produced in more back position than [e] and [æ] in SK (NK × [e]: β=–273.86, CI=–474.07−–73.65, p=.007; NK × [æ]: β=–261.86, CI=–457.58−–66.14, p=.009).
Significant interactions between Vowel type and Speech condition were also examined. Specifically, conversational speech condition affected the front vowels to be more backed and back vowels to be more fronted (e.g., [e] × Conversation: β=–153.08, CI= –287.84−–18.32, p=.026; [æ] × Conversation: β=–204.71, CI=–332.05− –77.36, p=.002; [o] × Conversation: β=179.86, CI=56.37–303.35, p=.004; [u] × Conversation: β=230.02, CI=104.93–355.10, p=.001). Similar to the F1 results above, casual speech style was elicited in conversational condition, indicating smaller vowel space.
Furthermore, we found a three-way interaction (NK × [æ] × Conversation: β=193.16, CI=14.07–372.25, p=.035). Specifically, the difference in F2 between NK and SK speakers for [æ] was influenced by conversational condition. The NK [æ] was produced in a more fronted position in conversational speech than SK [æ] in conversational speech. In the results, in the height (F1) dimension, the two-way interaction (Dialect × Vowel type) was significant for the three vowels ([e], [ʌ], and [o]). However, recall that the three-way interaction (Dialect × Vowel type × Speech condition) was not observed in the F1 dimension. In terms of the backness (F2) dimension, the two-way interaction (Dialect × Vowel type) was significant for [e] and [æ]. The three-way interaction was also significant (Dialect × Vowel type × Speech condition) only for [æ]. The main goal of the current analysis was to investigate to what extent NK and SK vowels are produced differently across speech conditions. Thus, in order to confirm the acoustic differences in NK and SK vowels, we examined whether F2 distinguishes the specific vowel types, focusing on each vowel contrast ([e]–[æ], [ʌ]–[o], [ɯ]–[u], and [o]–[u]), by conducting post-hoc test comparing the mean F2 values for these contrasts in each of the Dialect groups separately. The results from post-hoc analyses are presented in the next paragraph.
In the F2 dimension, because the three-way interaction (Dialect × Vowel type × Speech condition) was significant for [æ], speech condition was included in post-hoc analyses. The results are presented in Appendix 5 for NK and Appendix 6 for SK, respectively in Appendix.
First, starting with the NKs’ production, [e] and [æ] were not differentiated significantly in both careful and conversational speech (β=–21.89, SE=81, z=–0.27, p=1 for careful speech; β=–28.79, SE=58.1, z=–0.496, p=.9997 for conversational speech). Thus, the findings confirm that the NK [e] and [æ] are distinguished solely by the tongue height. In addition, [ʌ] and [o] were also not distinguished in both speech conditions (β=–120.71, SE=64.1, z= –1.883, p=.5627 for careful speech; β=–66.44, SE=22.8, z=–2.913, p=.0699 for conversational speech). Recall that [ʌ] and [o] were also not differentiated in the F1 dimension, which suggests that phonemic space of [ʌ] and [o] is substantially overlapped in both F1 and F2 dimensions. And this pattern is consistent with the previous findings (e.g., Lee et al., 2018). Moreover, although [ɯ]–[u] merger in the F2 dimension has been reported extensively in previous studies (e.g., Lee et al., 2018; Morgan, 2015), the NK [ɯ] and [u] were well-distinguished in the F2 dimension in both speech conditions (β=–400.06, SE=66.4, z=–6.025, p<.0001 for careful speech; β=–193.52, SE=30.3, z=–6.397, p<.0001 for conversational speech). Thus, in NK, [ɯ] maintains the mid-high position and [u] preserves the high-back position in the Figure 1 and 2. Finally, [o] and [u] were produced differently across the speech conditions. The tongue backness of [o] and [u] were not significantly distinguished in careful speech (β=–83.7, SE=65.8, z=–1.272, p=.9094). Specifically, both [o] and [u] were produced in back vowel position in careful speech. However, interestingly, in conversational speech, [u] was produced in a significantly more fronted position than [o] (β=–166.56, SE=28.3, z=–5.877, p<.0001). These findings were consistent with the results in Lee et al. (under review). This suggests that the fronting of [u] might be a result of vowel chain shifts, in order to be separated from the phonemic space of [o]. Given that the [o]–[u] merger has been reported in younger SK speakers’ vowel production (Han & Kang, 2013; Seong, 2004), the [o]–[u] contrast might be no longer in merger but in the process of ongoing sound change.
Recall that, in the F1 dimension, [o] was a mid-vowel while [u] was a high vowel. In the F2 dimension, the backness of NK [o] and [u] showed different patterns across the speech conditions. The [u] fronting is noteworthy because it is similar to the pattern that was observed in the SK production (e.g., Lee et al., under review and see also above). This may indicate that the NK [u] production might have been influenced by the speech condition (or the SK speaker). The F2 results indicate that, in NK, [o] is a mid-back vowel, and [u] is a high vowel but the [u] is produced in a more fronted position than the [o]. To sum up, [ʌ] and [o] were not distinguished in both F1 and F2 dimensions and the NK [o] was produced in a significantly lower position than the SK [o]. Thus, the findings suggest that the merger of [ʌ] and [o] may be occurring in a more fronted and lower position in NK (see the result Appendix 5).
Next, the post-hoc results for SK are reported in Appendix 6. In terms of SK, [e] and [æ] were also not differentiated in the F2 dimension in both speech conditions (β=–33.89, SE=80.2, z= –0.422, p=.99 for careful speech; β=–85.52, SE=64.3, z=–1.329, p=.888 for conversational speech). Thus, consistent with the previous findings, our findings confirm that the SK [e] and [æ] are merged in both F1 and F2 dimension (e.g., Sin et al., 2012). In addition, [ʌ] and [o] were not differentiated in the F2 dimension (β=–117.92, SE=63.1, z=–1.869, p=.5722 for careful speech; β=34.19, SE=29.6, z=1.154, p=.9446 for conversational speech). Recall that [ʌ] and [o] were differentiated in the F1 dimension in SK. And, also, note that the previous studies categorized both [ʌ] and [o] as back vowels in SK (e.g., Sin et al., 2012). Similarly, [ʌ] and [o] were majorly differentiated in the F1 dimension, consistent with the previous findings. Finally, similar to the NK patterns above, the [o]–[u] contrast was significantly influenced by speech conditions. For the F2 dimension, whereas [o] and [u] were not differentiated in the careful speech (β=–130.31, SE=64.6, z=–2.016, p=.471), they were significantly differentiated in the conversational speech (β=–180.47, SE=32.5, z=–5.558, p<.0001). Specifically, [u] was produced in a significantly more fronted position than [o] in conversational speech. Thus, given that both [o] and [u] were produced in high position, the findings demonstrated that [o] and [u] are now distinguished in the backness dimension in the SK of conversational speech, consistent with the findings in Lee et al. (under review).
Next, the second set of post-hoc pairwise tests comparing NK and SK revealed significant differences for F2 in vowel production. The post-hoc results are presented in Appendix 7. In comparison between NK and SK, the results from careful speech are presented first. In careful speech, degree of backness was similar across NK and SK (p>.05 for [i], [e], [æ], [ʌ], [o], [ɯ], [u], [a]). In other words, in careful speech, NK and SK vowel types were majorly different in the F1 dimension. On the other hand, in conversational speech, significant differences were observed for the F2 values. First, interestingly, backness of [a] was significantly different across NK and SK. The NK [a] was produced in significantly more fronted position than the SK [a] (β=–91.68, SE=43.2, z=–2.121, p=.0339). Given that [a] is categorized low-mid vowel in SK but low-back vowel in NK (e.g., Lee, 1991; Sin et al., 2012), we cannot interpret why the NK [a] was produced in a more fronted position than the SK. And also, it is challenging to explain why the NK [a] was more fronted than the SK [a] solely in conversational speech. This will be more elaborated in the discussion section. Moreover, the NK [ʌ] was also more fronted than the SK [ʌ] in the conversational speech (β= –146.49, SE=49.1, z=–2.983, p=.0029). Again, this pattern of [ʌ] was different from what we predicted. We hypothesized that the NK speakers may show vowel patterns to be more like their SK interlocutor. However, although backness of the NK [ʌ] was not different from that of the SK [ʌ] in careful speech, the pattern of NK [ʌ] became different in conversational speech. It is unclear why the NK speakers changed their production of [ʌ] in the opposite direction in conversational speech. And it is hard to interpret why their [ʌ] was different from the [ʌ] of careful speech which was similar to the SK [ʌ] at least in the backness dimension. We will also provide a more detailed explanation in the discussion section. Above, we observed that the NK [u] was more fronted in the conversational speech. However, the NK [u] was not different from the SK [u] in both speech conditions (β=–42.48, SE=70.6, z= –0.602, p=.5475 for careful speech; β=–31.95, SE=53.5, z=–0.597, p=.5505 for conversational speech). Given that the NK [u] was fronted, similar to the SK [u] in both speech conditions, the NK speakers did not necessarily produce the [u] to be more SK-like, by fronting the tongue, in the conversational speech. In this comparison, the important finding is that the backness of NK vowels were more similar to that of SK in careful speech; however, the backness of NK vowels became more diverged from that of SK vowels in conversational speech.
4. Discussion
The present study aimed to fill the gap in the literature by investigating the phonetic differences in vowel production between the standard varieties of North and South Korean. As predicted, production of [æ], [ʌ], and [o] was majorly different between NK and SK. First, we describe the findings of SK vowels in detail before discussing the NK vowels. The SK vowel production was consistent with the patterns that have been reported in the previous literature (e.g., Kang & Kong, 2016; Lee et al., under review; Sin et al. 2012). Thus, prior findings showed that SK speakers no longer differentiate [e] and [æ]. In addition, [o] was now produced in the high-back position where the [u] was used to be in (e.g., Han & Kang, 2013; Kang & Kong, 2016). More importantly, however; we found that [u] was more fronted than [o] in conversational speech, to be separated from the phonemic space of [o], showing the vowel change shifts (e.g., Lee et al, under review). The results from this study along with previous literature clearly indicated the current pattern of SK vowel production as follows: the [e]–[æ] pair has lost its contrast. The [o] is produced in high-back position and the [u] is moved away from its original position, by shifting into more fronted position than the [o].
Next, we found that NK speakers showed different patterns in vowel production. Specifically, they maintained a clear distinction in height between [e] and [æ], significantly lowering the tongue height for [æ] compared to [e]. This pattern was only observed in SK before 1990 (e.g., Umeda, 1999). Unlike SK, the [e] and [æ] have not undergone sound change (e.g., merger) in NK. Additionally, [ʌ] and [o] overlapped in both F1 and F2 dimensions. More importantly, [o] was produced in a significantly lower position than the SK [o] while [ʌ] was produced in a more fronted position than the SK [ʌ]. Thus, our findings indicate that the merger of [ʌ] and [o] occurs in the mid-back region, but with [ʌ] positioned slightly more frontward and [o] positioned lower compared to their SK counterparts. Consistently with the previous findings, our findings confirm that [ʌ] and [o] are merged in NK (e.g., Kang, 1996; Kang & Yun, 2018; Lee et al., 2018; Morgan, 2015), while the vowels are well-separated in SK.
More interestingly, [u] was produced in a more fronted position than [o] in conversational speech for both NK and SK speakers. Since conversational speech often reflects more innovative variants (Eckert, 2012; Labov, 2010), our data provide a real-time glimpse of ongoing vowel changes in both groups. The similarity between NK and SK speakers’ [o]–[u] production suggests that NK speakers may be adopting SK-like patterns in the conversational condition. This adaptation might result from assimilating the first author’s (SK interviewer) speech. However, it’s unclear why the NK speakers exhibit more progressive pattern for [o]–[u] contrast, exclusively, than other vowel contrasts.
Moreover, although the [ɯ]–[u] merger in NK in the F2 (backness) dimension has been discussed in previous studies (e.g., Kang, 1996; Lee et al., 2018), our findings did not show any possible merger between the two categories. The NK speakers well-maintained the [ɯ] in a mid-high position consistently and the position of NK [ɯ] had no difference from that of SK [ɯ]. Thus, the [ɯ]–[u] merger, reported previously, might be a context specific phonological feature. Future study can investigate the [ɯ]–[u] merger in more depth. Our findings summarized that the distinction of [e]–[æ] and the merger of [ʌ]–[o] may mark NK-like vowel features and be considered as NK accented vowels in SK community.
Next, we predicted that vowel production might be influenced by speech conditions. Recall that speech production is often affected by different speech styles (e.g., careful vs. conversational, see Labov, 2006). However, the effects of speech conditions were rather less evident in our findings. First, the effects of speech conditions on the F1 dimension were not significant in both NK and SK. In other words, the variations in speech conditions did not lead to any statistically significant changes in the F1 (height) dimension for both NK and SK, indicating that vowel height remains stable and consistent regardless of the speech conditions for these groups. In contrast, F2 of vowel production was significantly influenced by speech conditions. Given that the NK speakers were in a conversational setting with the first author who speaks SK, we hypothesized that they might adapt their vowel production to be more SK-like in the conversational speech. However, in our findings, those effects were not observed clearly. First, F1 of vowels were not affected by speech conditions significantly. More importantly, F2 of vowels were not different between NK and SK in careful speech; however, we observed the F2 differences in vowel types [a] and [ʌ] in conversational speech. The NK speakers produced [a] and [ʌ] in a more fronted position in the conversation than in the careful speech. The findings were unexpected. It is unknown why they modified the frontness of tongue for [a] and [ʌ]. Note that the vowel [a] is often considered a stable and clear vowel, not only in Korean but also in many languages. It is used as a reference vowel and a filler in perception experiments (Hillenbrand et al., 1995; Johnson, 2003; Ladefoged, 2001). Given that the previous literature reported [a] is produced consistently clear and stable, it is unclear why the NK [a] was moved to a more fronted position in conversational speech. Nonetheless, specifically in the conversational speech, the NK speakers changed the production of even the stable vowel type [a] and [ʌ] in a direction to be different from the SK [a] and [ʌ]. This might be related to their vulnerability and unstable status in SK community. Specifically, the production of [a] and [ʌ] in more fronted position might present acoustic features of hypercorrection. It has been reported that nonstandard speakers often show hypercorrection in production. Previous studies have presented that nonstandard speakers have social pressure to speak more clearly, in order to avoid mistakes and appear clearer in production (Edwards, 1999). Because they often feel insecure about their language use, they overcompensate by hypercorrecting their pronunciation; however, unfortunately, this hypercorrection leads more misunderstanding between standard and nonstandard speakers (Chambers & Trudgill, 1998; Foulkes & Docherty, 1999; Lippi-Green, 2012; Milroy & Milroy, 1999; Tannen, 1984; Trudgill, 1989). For example, hypercorrection often occurs in an incorrect manner that is different from the production of standard speakers. Because nonstandard speakers are not familiar with standard variants but feel insecure about their language use, they made effort to deliver their pronunciation more clearly to standard speaker (Edwards, 1999; Trudgill, 2000). However, despite the intentions of nonstandard speakers, standard listeners are more likely to misinterpret the hypercorrections that were made from nonstandard speakers. This is primarily due to the unexpected and inconsistent nature of hypercorrected speech forms, leading greater confusion in conversation (Chambers & Trudgill, 1998; Foulkes & Docherty, 1999; Lippi-Green, 2012; Milroy & Milroy, 1999). Thus, the fronting of [a] and [ʌ] in NKs’ production may represent the patterns of hypercorrection. Future study can examine the hypercorrection of [a] and [ʌ] in NK in more depth.
Acoustic differences between NK and SK were examined in careful and conversational speech styles. Our results indicated that the four vowel types ([æ], [ʌ], [o], and [a]) were majorly different between NK and SK. The distinction in vowel height maintained by NK speakers between the [e] and [æ] vowels. The merger of [ʌ]–[o] and fronting of [a] were observed. We also observed significant effects of speech condition on vowel production; however, different from the hypotheses, the NK speakers did not change their production to be more-like SK in the conversational speech.
Future research could build on these findings by conducting production studies, including other phonetic features and examining how these differences are perceived by speakers of each variety. First, for the production study, given that the [e]–[æ] distinction was an old form that was observed in SK in the past, it is possible that the [y] and [ø] might have not diphthongized but still be monophthongs in NK, by presenting more conservative vowel production form. Future study can investigate production of [y] and [ø] in NK, analyzing whether those vowels are diphthongized in NK refugees’ speech. Moreover, the production of [y] and [ø] might be studied with sociolinguistic factors such as AoA, LoR, degree of adaptation of NK speakers in SK community. The current study did not focus on how such factors influence the NKs’ vowel production. Further study can analyze relations between sociolinguistic factors and acquisition of SK-like vowel production.
Next, future study can conduct perception studies to determine to what extent SK listeners identify the NKs’ distinguished [e] and [æ] and merged [ʌ] and [o]. The confusability of the vowel pairs can be compared between NK listeners and SK listeners through perception experiments. Furthermore, to what extent SK listeners rate the accentedness of distinguished [e] and [æ] and merged [ʌ] and [o] from the NK speakers.
The phonetic differences identified in this study have significant implications for the understanding of linguistic divergence within the Korean Peninsula. These findings contribute to the broader field of dialectology by illustrating how geopolitical separation can lead to distinct phonetic divergence. From a practical perspective, understanding these phonetic distinctions is crucial for supporting North Korean refugees in their adaptation to life in South Korea. Knowledge of these differences can inform language education programs and help linguists develop targeted strategies to aid refugees in acquiring the South Korean dialect. This is particularly important given the role of second dialect acquisition in social integration and identity formation.